[log-10] 지식 — 4모델 중간 비교 (Kanana 36/60)
4개 omni 모델의 지식 실험 중간 결과(Kanana 36/60)와 그 안에서 보이는 패턴들 정리.
실험 설계와 연구 질문은 log-00 참조.
RQ1(모달리티 갭 존재 여부)과 RQ2(한국어 특화 vs 공통 현상)에 대한 중간 보고. (RQ3은 감정 실험이 설계되면 별도로 다룰 예정)
중간 결과
전체 n=1100 비교
각 모델이 처리한 전체 샘플 기준, 현재까지 Kanana는 36/60, 나머지는 전체 n=1100과 비교.
| 모델 | 파라미터 | 한국어 특화 | text | image | audio | 불일치 |
|---|---|---|---|---|---|---|
| HCX-SEED-Omni | 8B | ✅ | 49.4% | 27.8% | 27.8% | 75.2% |
| Kanana-1.5-o | 11.6B | ✅ | 38.9% | 25.0% | 27.8% | 77.8% |
| MiniCPM-o 2.6 | 8B | ❌ | 36.5% | 23.7% | 24.5% | 88.2% |
| Qwen2.5-Omni | 7B | ❌ | 33.0% | 29.1% | 27.5% | 82.0% |
Kanana는 36샘플 기준(audio 에러 2건 포함, 오답 처리). 비교 모델은 전체 n=1100. 에러 제외 시: Kanana audio 29.4%, 불일치 76.5% / MiniCPM audio 24.5%, 불일치 88.2%
표본 개수 공정 비교 (Kanana 완료 기준 36개에 대한 성능 확인)
| 모델 | text | image | audio | 불일치 |
|---|---|---|---|---|
| HCX-SEED-Omni | 52.8% | 41.7% | 41.7% | 63.9% |
| Kanana-1.5-o | 38.9% | 25.0% | 27.8% | 77.8% |
| MiniCPM-o 2.6 | 33.3% | 22.2% | 16.7% | 88.9% |
| Qwen2.5-Omni | 19.4% | 19.4% | 22.2% | 77.8% |
에러 제외 시: Kanana audio 29.4%, 불일치 76.5%
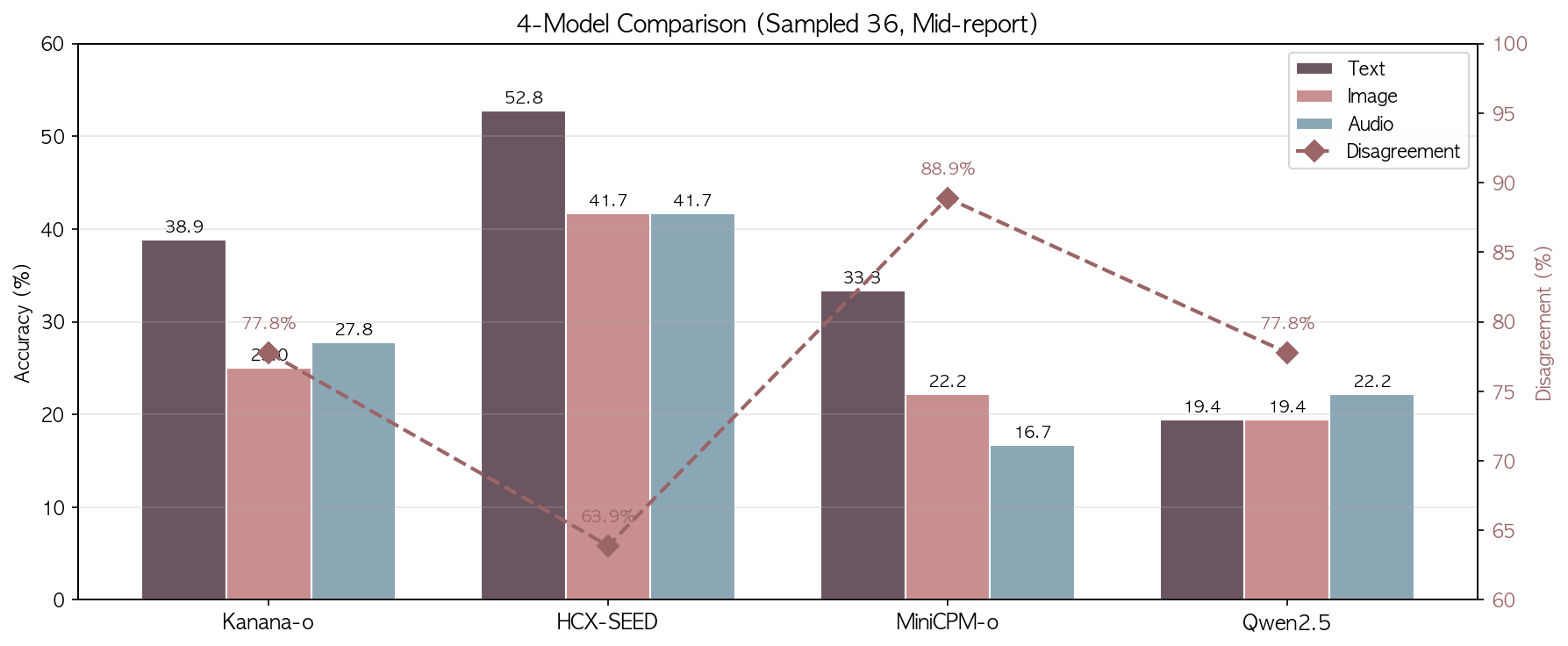
분석
1. 한국어 특화가 전 모달리티에서 유효하다
가장 뚜렷한 패턴은 한국어 특화 모델(HCX, Kanana)이 비특화 모델(MiniCPM, Qwen)을 전 모달리티에서 앞선다는 것이다. 이건 텍스트만이 아니라 이미지(= 한국어 OCR)와 오디오(= 한국어 ASR) 조건에서도 마찬가지다. KMMLU가 한국어 지식을 요구하는 벤치마크인 만큼 당연한 결과로 보일 수 있지만, 모달리티별로 나눠 봤을 때도 이 우위가 일관되게 유지된다는 점을 주요하게 지적하고 싶다.
비한국어 모델에서는 “modality gap”와 별개로 “한국어 처리 성능의 한계”가 존재하기 때문에, 갭 패턴 해석이 오염된다. Qwen은 샘플링셋에서 text 19.4%로, 텍스트를 직접 읽는 것조차 거의 찍기 수준(25%)과 다르지 않다.
2. HCX > Kanana — 벤치마크는 만능이 아니다
Kanana가 KoNet 89.44로 HCX(75.39)를 크게 앞서지만, KMMLU 지식 QA에서는 HCX가 전 모달리티에서 Kanana를 능가한다. 텍스트 기준 49.4% vs 38.9%로 10포인트 이상 차이가 난다.
KoNet은 CSAT(수능) 기반이고 KMMLU는 전문 지식 도메인이다. Kanana가 KoNet에서 강한 건 CSAT 스타일의 한국어 독해·VQA에 최적화됐기 때문일 수 있고, HCX가 KMMLU에서 강한 건 전문 지식 커버리지가 넓기 때문일 수 있다. 어느 쪽이든, 단일 벤치마크 점수로 모델의 전반적 능력을 판단하는 건 위험하다는 교과서적 교훈이 데이터로 확인된다.
참고로 Kanana-1.5-o 모델 카드에서는 KMMLU 점수를 보고하지 않는다. 텍스트 전용 Kanana-1.5-8B base에서 KMMLU 48.94(5-shot)가 보고되지만, 우리 실험은 omni 모델에 0-shot이라 직접 비교는 불가능하다. 다만 omni화 과정에서 텍스트 전용 대비 지식 QA 능력이 어느 정도 희석됐을 가능성은 열어둘 수 있을 것이다.
3. text > image/audio — 그러나 갭의 크기와 방향이 다르다
전체셋 기준, HCX는 text 49.4% → image/audio 27.8%로 21.6포인트의 급격한 갭을 보인다. Kanana는 text 38.9% → image 25.0% / audio 27.8%로 텍스트 우위는 있지만 갭이 상대적으로 작고, 특히 audio가 image보다 높다.
Qwen은 text(33.0%)와 image(29.1%)의 갭이 3.9포인트에 불과하다. 다른 모델 대비 text-image 갭이 가장 작은데, image 정확도 29.1%는 4모델 중 가장 높은 수치이기도 하다. 모달리티 간 정렬이 실제로 고른 것인지, 아니면 한국어 텍스트 처리 약점이 image 조건에서 상쇄되는 것인지는 이 데이터만으로 구분하기 어렵다. Qwen의 representation 처리가 어떻게 되는지 확인해봐야 할 듯.
4. 불일치율 67~92% — 어떤 omni 모델도 진정한 omni가 아니다
3모달 불일치율은 HCX 63.9%에서 MiniCPM 91.7%까지 분포한다(샘플링셋 기준). 랜덤 baseline(각 모달리티에서 독립적으로 4지선다 찍기)의 기대 불일치율이 약 94%임을 감안하면, MiniCPM은 사실상 모달리티 간 응답이 거의 독립적이라는 뜻이다.
가장 일관적인 HCX조차 36%의 샘플에서만 모든 모달의 응답이 일치한다. 동일한 정보를 다른 형식으로 넣었을 뿐인데 3번 중 2번은 답이 달라진다. “Omni”라는 레이블이 사용자에게 주는 기대치 대비 현실의 갭이 크다.
5. Kendall’s tau — 모달리티 간 내부 경로의 단서
| 모델 | txt-img | txt-aud | img-aud |
|---|---|---|---|
| HCX | 0.020 | 0.020 | 1.000 |
| Kanana | 0.066 | 0.269 | 0.072 |
| MiniCPM | 0.026 | 0.035 | 0.205 |
| Qwen | 0.206 | 0.157 | 0.202 |
비교 모델은 1100셋, Kanana는 36/60 기준. 에러는 오답 처리.
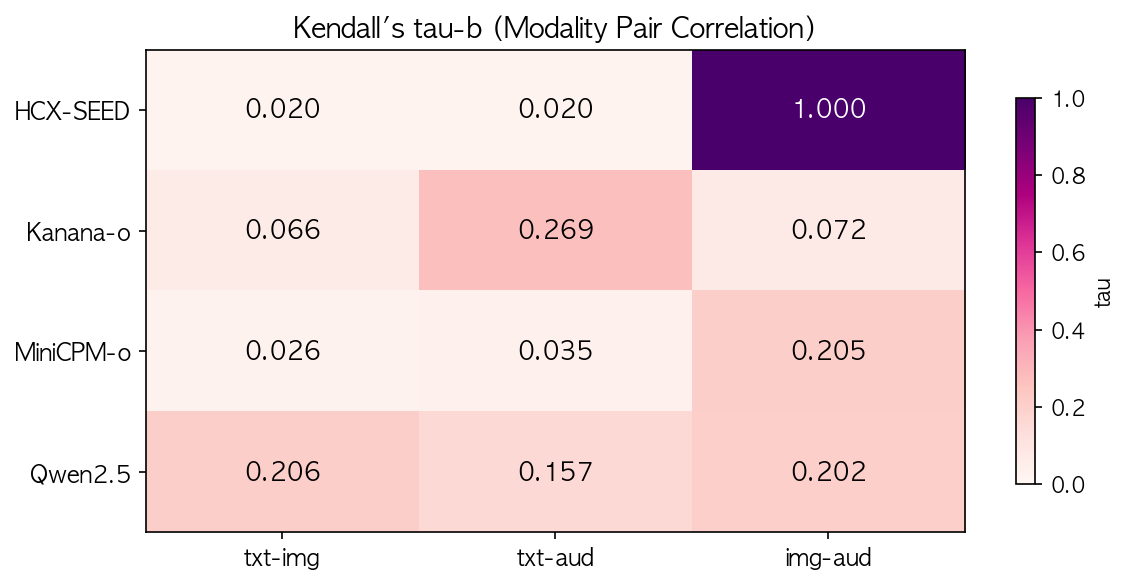
HCX의 img-aud tau = 1.000이 가장 눈에 띈다. 이미지와 오디오에서 맞히고 틀리는 패턴이 완벽히 일치한다. 1,100샘플에서 1.000이라는 건 통계적 우연이 아니라, 두 모달리티가 LLM core에 도달하기 전에 거의 동일한 내부 표현으로 수렴하고 있다는 강력한 증거다. 반면 텍스트와는 tau 0.020으로 거의 독립적. 텍스트 경로와 비텍스트 경로가 사실상 별개의 파이프라인으로 동작하는 셈이다.
Kanana의 txt-aud tau 0.269는 4개 모델 중 텍스트-오디오 상관이 가장 높다. Kanana의 한국어 ASR 강점(KsponSpeech CER 6.45)이 오디오에서 내부 텍스트 표현으로의 변환 충실도를 높여, 텍스트 직접 입력과 유사한 정오답 패턴을 만들어내는 것으로 추정된다.
Qwen은 모달리티 간 상관이 가장 균등하다 (0.16~0.21). 특정 모달리티 쌍이 강하게 결합되지 않고, 셋 다 비슷한 수준으로 정보를 공유한다. 아키텍처적으로 모달리티 fusion이 가장 고른 설계일 가능성이 높아보인다.
6. 도메인별 분석 — History vs Law
| Korean-History | Law | |||||
|---|---|---|---|---|---|---|
| 모델 | text | image | audio | text | image | audio |
| HCX | 43.0% | 31.0% | 31.0% | 50.0% | 27.5% | 27.5% |
| Kanana | 38.9% | 22.2% | 41.2% | 38.9% | 27.8% | 17.6% |
| MiniCPM | 32.0% | 31.0% | 26.5% | 36.9% | 23.0% | 25.2% |
| Qwen | 26.0% | 31.0% | 29.0% | 33.7% | 28.9% | 27.3% |
전체셋 기준. Kanana는 History 17개, Law 17개.
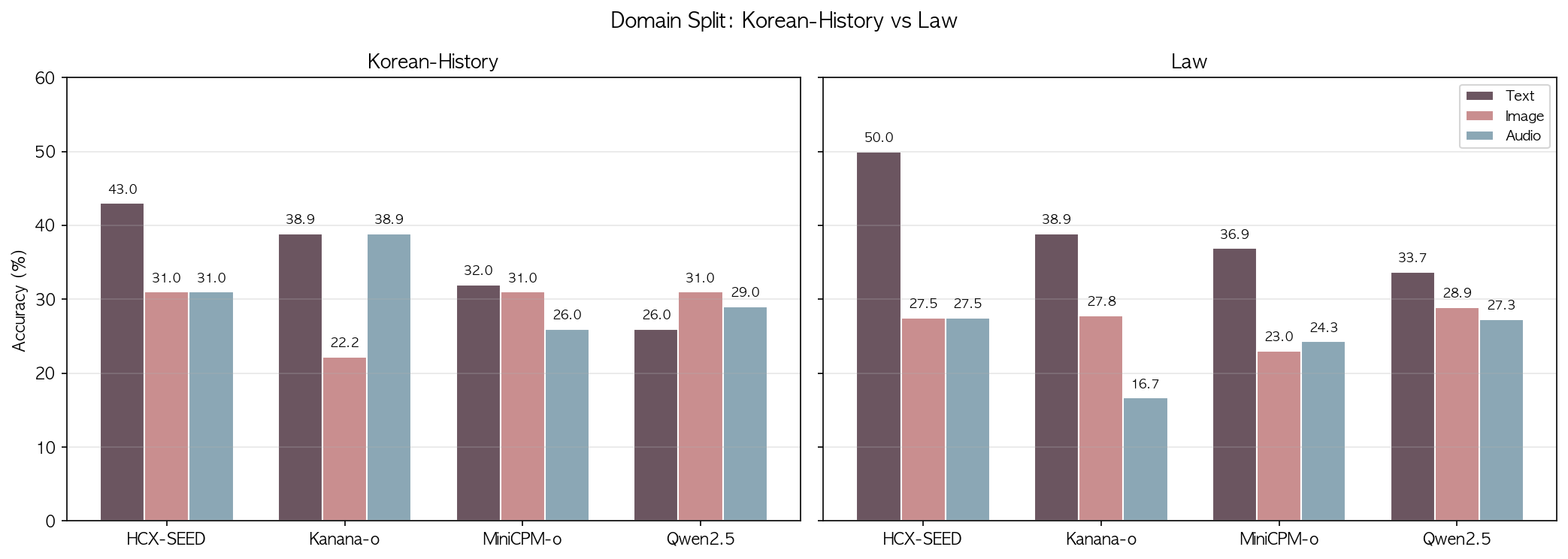
Kanana에서 도메인별 모달리티 갭 방향이 역전된다. History에서는 audio(41.2%) > text(38.9%)인데, Law에서는 text(38.9%) > audio(17.6%)로 24포인트 차이가 난다. History 문제는 맥락 서술이 많아 음성의 자연스러운 흐름이 이해를 돕고, Law 문제는 조문 번호나 항목 구조 등 시각적 구조에 의존하는 정보가 많아 음성으로 전달하기 어려운 것이라고 해석하는게 타당할까?
이 역전은 아직 17개 샘플 기준이라 확정적이지 않지만, 분석의 여지는 남아있다. 또한 RQ3(과제 유형별 갭 차이)에 대한 예비 증거로서 주목할 만하다고 생각한다. 감정 실험 전에도 이미 도메인 특성에 따라 모달리티 갭 패턴이 달라진다는 신호가 보인다.
기술적 제약과 노이즈
- Kanana API 쿼터 제약: 제한된 일일 호출량으로 분할 진행 중. 비교 모델은 로컬 GPU로 수시간 만에 1,100샘플 처리 완료 — 데이터 크기의 비대칭이 있다.
- Audio 60초 제한: Law 문제 중 텍스트가 긴 경우 TTS가 60초를 초과하여 API 에러 발생. 현재 36샘플 중 2건 에러.
- 이미지 렌더링 = OCR 테스트: 텍스트를 PNG로 렌더링한 것이므로 자연 이미지 이해 능력과는 다른 축을 측정한다.
현재까지의 결론
- 모든 omni 모델에서 모달리티 갭이 존재한다. 이건 Kanana 고유 현상이 아니라 omni 모델 공통 현상이다(RQ2에 대한 중간 답).
- 한국어 특화 모델이 전 모달리티에서 우위이지만, 그 안에서의 갭 패턴은 모델마다 다르다. HCX는 img-aud가 완전 동기화되어 있고, Kanana는 txt-aud가 상대적으로 일관적이다.
- 벤치마크 점수와 실제 task 성능의 괴리가 확인된다. Kanana의 KoNet 우위가 KMMLU에서는 재현되지 않는다.
- 도메인에 따라 모달리티 갭 방향이 바뀔 수 있다 — History에서의 audio 우위는 감정 실험에서 더 뚜렷해질 가능성이 있다.
남은 것
- 지식 실험 Kanana 24샘플 추가 완료 — 4일 후 60/60 도달 예정. 최종 비교 확정.
- 감정 실험 설계 — 감정 음성 데이터셋(KEMDy20, K-EmoCon 등) 기반, 모달리티 고유 정보가 존재하는 과제에서 갭 패턴이 어떻게 달라지는지 검증.
- 시각화 — 히트맵, 레이더 차트 등 패턴을 직관적으로 보여줄 시각 자료.
Personal note. 36/60 시점에서의 중간 보고다. Kanana API 쿼터 제약 때문에 분할 진행하다 보니 비교 모델 대비 데이터 비대칭이 있고, 이 포스트의 Kanana 수치는 60개 완료 후 달라질 수 있다. 그럼에도 이 시점에서 정리한 의도는, 36개만으로도 모달리티 갭의 존재 자체는 충분히 확인되었고, 모델 간 갭 패턴의 차이(HCX의 img-aud 동기화, Kanana의 txt-aud 상관 등)가 이미 뚜렷하게 나타나고 있기 때문이다. 최종 비교는 완료 (60/60) 후 별도로 다룰 예정.