[log-13] 지식 — 완료 (60/60)
지식 실험 완료 (60/60). API 쿼터를 추가로 받아 남은 6문제를 한 번에 처리했다. 에러 처리 방식을 변경하여 과거 로그 수치도 소급 수정했다.
오늘 결과 (6문제)
| ID | text | image | audio | 정답 |
|---|---|---|---|---|
| Law-980 | 3 ✅ | 3 ✅ | 3 ✅ | 3 |
| Law-781 | 4 ✅ | 2 ❌ | 3 ❌ | 4 |
| Law-747 | 2 ✅ | 2 ✅ | 2 ✅ | 2 |
| Korean-History-029 | 4 ❌ | 3 ✅ | 4 ❌ | 3 |
| Law-348 | 2 ✅ | 3 ❌ | 3 ❌ | 2 |
| Korean-History-031 | 3 ❌ | 3 ❌ | 1 ✅ | 1 |
| 모달리티 | 정답률 |
|---|---|
| 텍스트 | 4/6 = 66.7% |
| 이미지 | 3/6 = 50.0% |
| 음성 | 3/6 = 50.0% |
Law-980과 Law-747은 3모달 전부 정답. 60문제 중 3모달 완전 일치 정답은 많지 않았는데, 마지막 배치에서 2건이 나왔다.
Law-781과 Law-348은 text만 정답을 맞힌 패턴으로, 비텍스트 모달리티가 동기화되어 같은 방향으로 틀리는 기존 패턴이 반복된다.
KH-029는 반대로 image만 정답, KH-031은 audio만 정답으로 드문 케이스다.
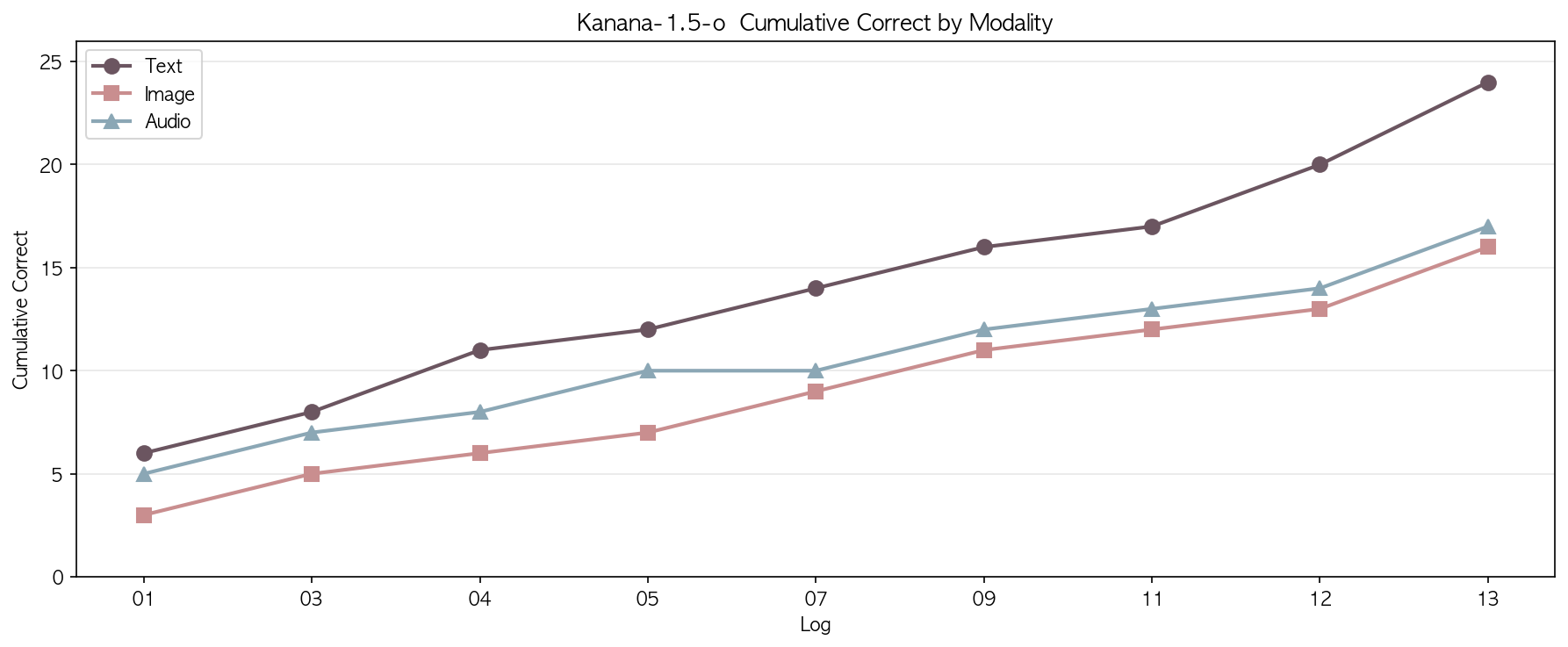
최종 누적 (60/60)
| 모달리티 | 정답률 |
|---|---|
| 텍스트 | 24/60 = 40.0% |
| 이미지 | 16/60 = 26.7% |
| 음성 | 17/60 = 28.3% |
| 음성* | 17/57 = 29.8% |
*에러 3건을 제외한 수치.
text > audio > image 순서는 끝까지 유지되었다. 전일(54/60) 대비 text가 37.0%에서 40.0%로 반등했고, image도 24.1%에서 26.7%로 올랐다. 표본이 작아서 마지막 배치의 정답률이 높았던 영향이 그대로 반영된다.
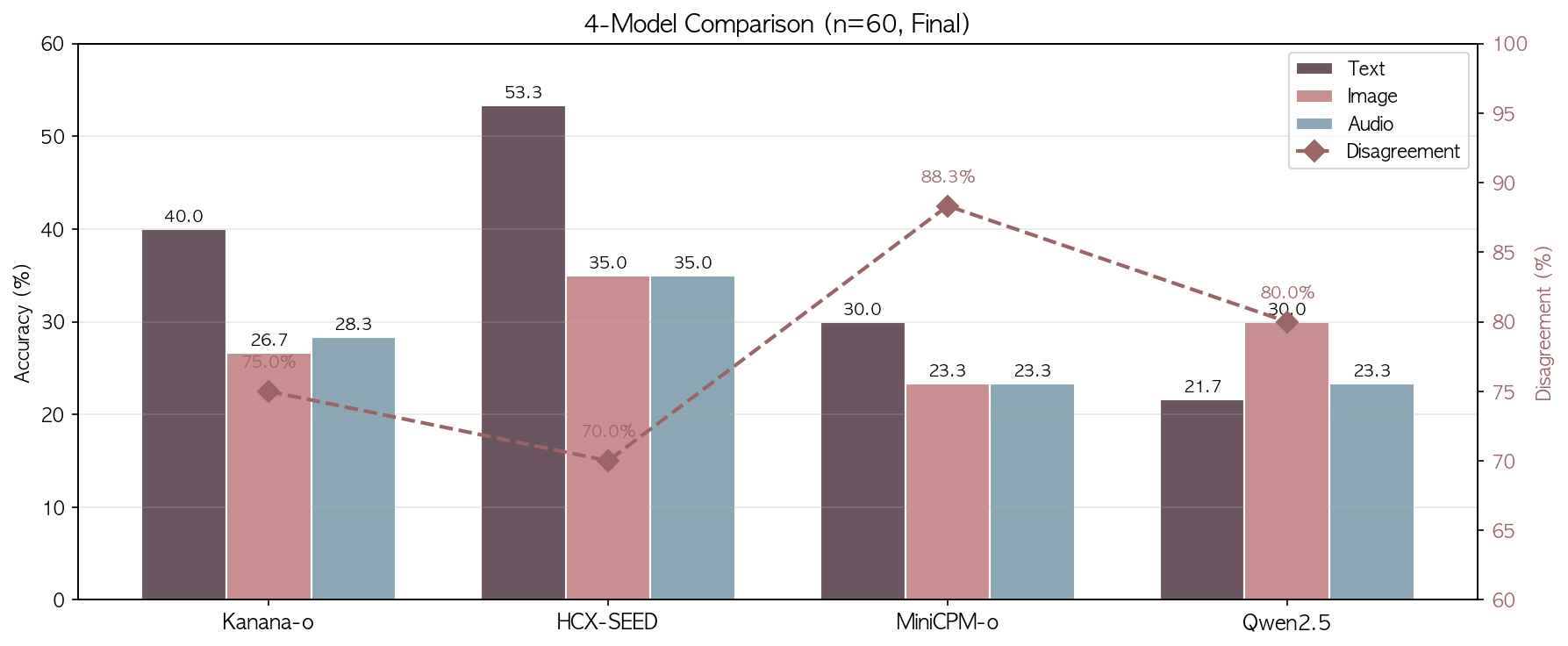
4모델 최종 비교 (동일 60샘플)
| 모델 | text | image | audio | 불일치 |
|---|---|---|---|---|
| HCX-SEED-Omni | 53.3% | 35.0% | 35.0% | 70.0% |
| Kanana-1.5-o | 40.0% | 26.7% | 28.3% | 75.0% |
| MiniCPM-o 2.6 | 30.0% | 23.3% | 23.3% | 88.3% |
| Qwen2.5-Omni | 21.7% | 30.0% | 23.3% | 80.0% |
에러 제외 시: Kanana audio 29.8%, 불일치 73.7% / MiniCPM audio 23.7%, 불일치 88.1% / Qwen image 31.6%, 불일치 78.9%
비교 모델 전체셋 (n=1100)
| 모델 | text | image | audio | 불일치 |
|---|---|---|---|---|
| HCX-SEED-Omni | 49.4% | 27.8% | 27.8% | 75.2% |
| MiniCPM-o 2.6 | 36.5% | 23.7% | 24.5% | 88.2% |
| Qwen2.5-Omni | 33.0% | 29.1% | 27.5% | 82.0% |
Kanana는 API 쿼터 제약으로 60샘플 한정. 비교 모델은 로컬 GPU로 전체 n=1100 실행.
n=1100에서는 전 모델 공통으로 text > image > audio 경향이 확인된다. 60샘플에서 보였던 Qwen의 text(21.7%) < image(30.0%) 역전은 n=1100에서 text 33.0% > image 29.1%로 정상화되어 표본 노이즈로 판단한다(log-06 참조). HCX는 n=1100에서 image/audio가 27.8%로 60샘플(35.0%) 대비 -7.2%p 하락하여 모달리티 갭이 더 심화된다.
Kendall’s tau (60샘플 공통)
| 모델 | txt-img | txt-aud | img-aud |
|---|---|---|---|
| HCX | 0.126 | 0.126 | 1.000 |
| Kanana | 0.200 | 0.242 | 0.206 |
| MiniCPM | -0.103 | -0.275 | 0.441 |
| Qwen | 0.274 | 0.379 | -0.017 |
Kendall’s tau (n=1100, Kanana는 60)
| 모델 | txt-img | txt-aud | img-aud |
|---|---|---|---|
| HCX | 0.020 | 0.020 | 1.000 |
| Kanana | 0.200 | 0.242 | 0.206 |
| MiniCPM | 0.026 | 0.035 | 0.205 |
| Qwen | 0.206 | 0.157 | 0.202 |
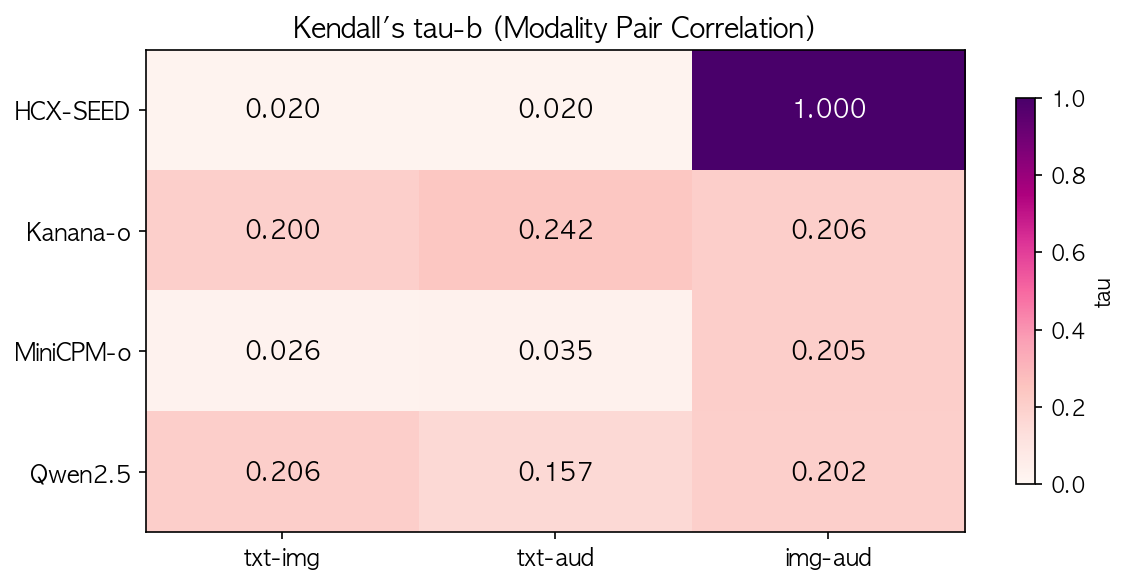
HCX의 img-aud = 1.000은 60샘플에서도 n=1100에서도 동일하다. 이미지와 오디오의 정오답 패턴이 완벽히 일치하며, 두 모달리티가 사실상 같은 내부 경로를 타는 것으로 추정된다. Kanana의 txt-aud 0.242는 4모델 중 텍스트-오디오 상관이 가장 높아 한국어 ASR 강점이 반영된 것으로 보인다. 60샘플에서 Qwen txt-aud 0.379, MiniCPM img-aud 0.441 등 높게 나타난 값들은 n=1100에서 각각 0.157, 0.205로 크게 하락하여 표본 노이즈임이 확인된다.
불일치 분해
불일치율을 좀 더 세분화해보았다. 3모달의 응답 일치 여부와 정답 여부를 교차하면 네 가지 범주가 나온다.
| 모델 | Agree + Correct | Agree + Wrong | Gap (recoverable) | Gap (random) |
|---|---|---|---|---|
| HCX-SEED-Omni | 21.7% | 8.3% | 45.0% | 25.0% |
| Kanana-1.5-o | 11.7% | 13.3% | 51.7% | 23.3% |
| MiniCPM-o 2.6 | 1.7% | 10.0% | 56.7% | 31.7% |
| Qwen2.5-Omni | 6.7% | 13.3% | 45.0% | 35.0% |
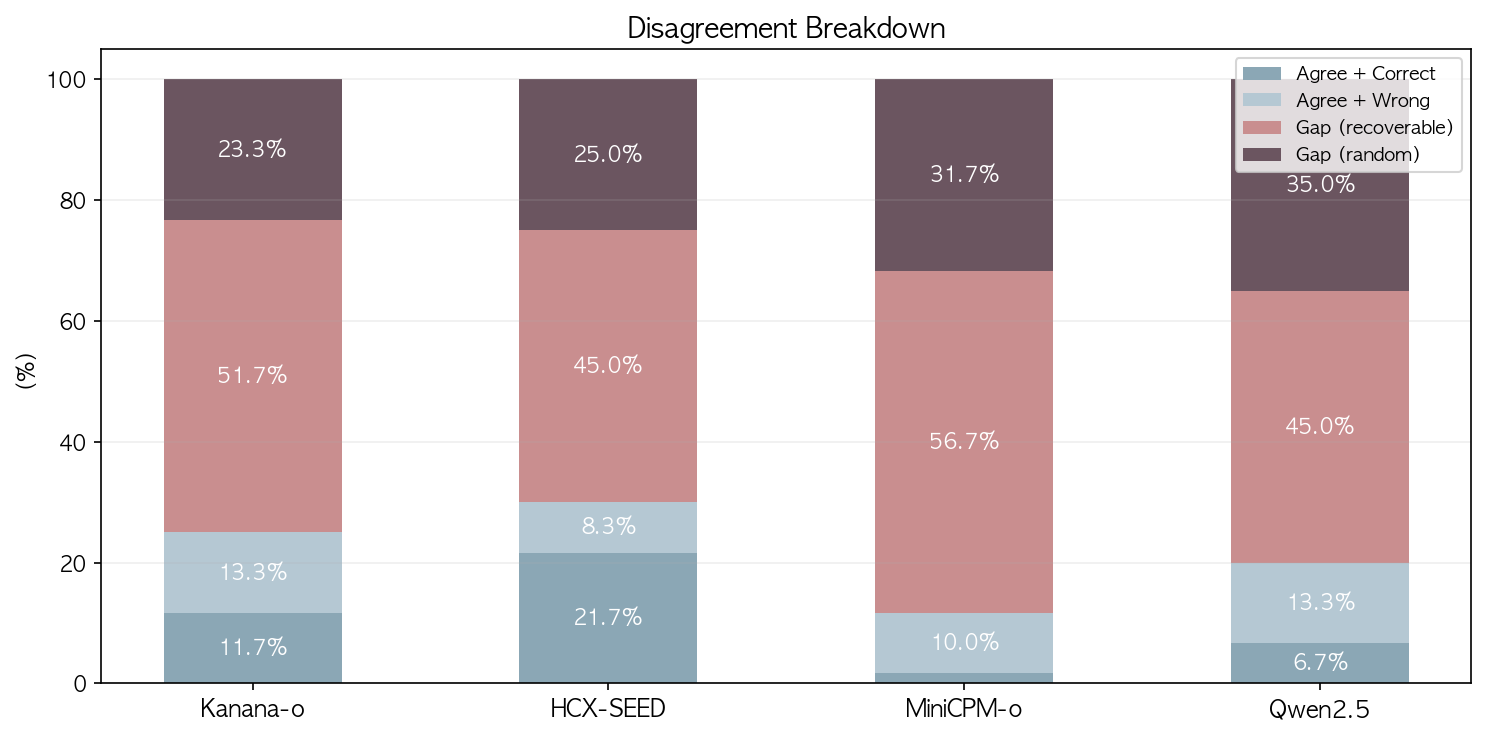
Agree + Correct는 3모달이 같은 답을 내고 그것이 정답인 경우다. HCX가 21.7%로 가장 높고, MiniCPM은 1.7%에 불과하다.
Agree + Wrong은 3모달이 같은 오답에 수렴한 경우다. 모달리티 간 갭은 없지만 모델 자체가 틀린 것이다. Kanana와 Qwen이 13.3%로 가장 높은데, 확신을 갖고 틀리는 문제가 적지 않다는 의미다.
Gap (recoverable)은 모달리티 간 답이 다르지만, 적어도 하나는 정답에 도달한 경우다. 모달리티 갭의 핵심으로, 올바른 모달리티를 선택하거나 앙상블할 경우 정답 회수가 가능한 영역이다. 전 모델에서 가장 큰 비중(45~57%)을 차지한다. MiniCPM이 56.7%로 가장 높은데, 이는 정확도 자체가 낮아서 맞는 모달리티와 틀리는 모달리티의 편차가 크기 때문이다.
Gap (random)은 모달리티 간 답이 다르면서 전부 오답인 경우다. 모르는 문제에서 모달리티마다 다른 방향으로 추측하는 것으로, 랜덤 노이즈에 가깝다. Qwen이 35.0%로 가장 높다. 한국어 지식이 부족한 상태에서 모달리티별로 서로 다른 오답을 내는 패턴이다.
에러 처리 방식 변경
기존에는 API 에러로 응답을 받지 못한 샘플을 분모에서 제외했다. 이번 로그부터 에러를 오답으로 처리하는 방식으로 변경했다. 모델이 해당 입력을 처리하지 못한 것 자체가 실패이므로, 제외보다 오답 처리가 공정하다는 판단이다.
에러 내역:
- Kanana audio 3건 (Law-549, KH-071, Law-387): 렌더링된 음성 파일이 60초를 초과하여 API에서 거부됨
- MiniCPM audio 1건 (Law-348): 파싱 실패
- Qwen image 3건 (KH-013, KH-025, KH-064): CUDA OOM으로 추론 실패
이에 따라 과거 로그(log-07, 09, 10, 11, 12)의 수치도 소급 수정했다. 누적 테이블에는 에러 제외 수치를 음성* 행으로 병기해두었다.
영향 범위:
- Kanana audio: 분모가 에러 건수만큼 증가 (예: 36/60 시점 10/34→10/36)
- MiniCPM 1100셋 audio: 25.3%→24.5%, 불일치 87.2%→88.2%
- Qwen 60셋 image: 31.6%→30.0%
API 쿼터 확장
기존 쿼터로는 진행이 느려서 추가 쿼터를 발급받았다. call_manager.py에 키 자동 전환 로직을 추가하여 기존 쿼터 소진 시 자동 전환된다. 감정 실험에서 본격적으로 활용할 예정이다.
다음 단계
지식 실험 데이터 수집이 완료되었으므로 감정 실험으로 넘어간다. 확장된 쿼터로 감정 실험 진행 속도가 빨라질 것이다.