카카오톡 채팅형 AI 서비스 비교 분석
H2HMem 리뷰하면서 든 생각의 정리. 논문의 설정이 이미 카카오톡의 실제 채팅 AI들과 맞닿아 있다는 관찰에서 출발한다. 이어지는 연구 구상은 별도로 정리 예정.
Motivation
H2HMem이 다루는 문제는 AI를 대화의 참여자가 아니라 옆에서 대화를 지켜보는 관찰자(observer)로 세워두고, 사람들끼리(human-human) 주고받는 대화를 얼마나 잘 기억했다가 나중의 질문에 답하는지를 측정한다는 것으로 요약할 수 있다.
이 설정이 낯설다고 한다면 거짓말일 것이고, 대화 밖에서 대화를 관측하고 상태를 추적한다는 그림은 초기 대화시스템 연구가 오래 붙들던 구도이기도 하기 때문이다.
지금 이 그림이 다시 연구 트렌드로 눈길을 끄는 이유는 최근 카카오톡에 들어온 두 개의 대화형 AI 서비스가, “대화 밖에서 대화를 다루는” 이 방식을 고민하고 있기 때문이다. 연구도 어느 정도는 회귀하는 측면도 없지 않은 듯.. 이래서 시간이 깡패인가?
그 둘은 채팅방의 @ChatGPT 챗봇과 카카오의 초개인화 AI 카나나다. 둘 다 카카오가 if(kakaoAI)2024에서 내건 “다양한 관계와 대화 속에서 개인의 맥락과 감정까지 고려하는” 그룹 AI 비전 아래 2024–2026년에 걸쳐 공개 및 배포된 서비스다. (여기서 말하는 카나나는 모델 패밀리가 아니라 그 위에 올라간 앱 혹은 서비스 쪽을 가리킨다. 이름이 같아 헷갈릴 수 있지만, 기존의 페르소나 캐릭터 느낌으로 접근했던 서비스가 foundation 모델과 함께 발전되어 개인화 AI Assistant에 가깝게 포지셔닝하고 있다고 느낀다.)
두 서비스가 한 좌표평면의 대각으로 갈라져 있다는 사실 자체가 이 포스트에서 전하고자 하는 통찰의 출발점으로, 두 서비스를 최신 벤치마크인 H2HMem과 비교 분석해보고자 한다.
카카오톡의 두 대화형 AI 서비스
1. 채팅방 @ChatGPT 챗봇: reactive tool
2026년 6월에 등장한 최신 기능으로, 채팅방에 챗봇을 추가하고 입력창에서 @ChatGPT ... 로 멘션하면, 건넨 프롬프트에 대해 그 자리에서 응답한다 (카카오 공식, AI타임스).
눈여겨볼 지점은 이 챗봇이 오가는 대화를 기억하지 않는다는 데 있다. @ChatGPT 바다 풍경 그려줘나 @ChatGPT 뉴스처럼, 응답은 어디까지나 유저가 직접 건넨 명령에 대한 것으로 한정하고 있어, 채팅방 안에서 대화를 지켜보는 관찰자라기보다, 호명하면 잠깐 소환됐다 사라지는 참여자형 도구에 가깝다. 발화의 트리거는 전적으로 사용자가 쥐고 있는 셈이다.
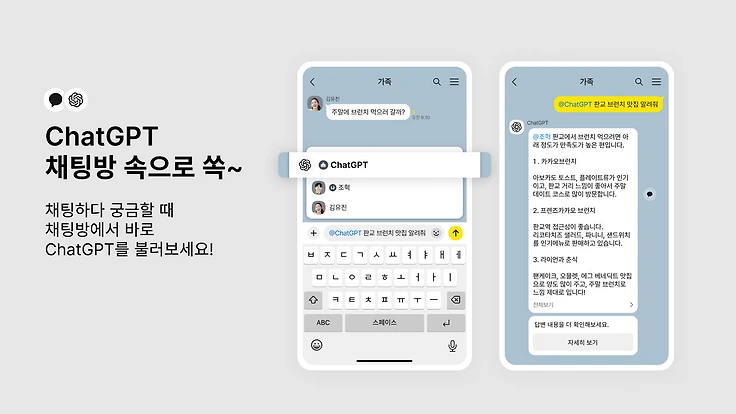
@ChatGPT 챗봇: 멘션으로 호출할 때만 응답(reactive)하고, 그 응답은 참여자 모두에게 보인다(public). (이미지 출처: 카카오 공식)2. 카나나: proactive observer
카카오의 초개인화 그룹 AI 앱 카나나가 정확히 반대편에 선다. 카나나는 상주하는 그룹대화의 내용을 지속적으로 관측하고 기억하면서 요약/일정 정리/정보 추천 등을 얹는다 (카카오 CBT 안내). (초기엔 그룹메이트 ‘카나’·개인메이트 ‘나나’로 역할을 나눠 소개했지만, 현재는 ‘카나나’로 통칭한다.)
꽤 흥미롭게 소개된 지점은 예를 들어 함께 읽은 논문을 두고 스터디방에 먼저 퀴즈를 던지거나, 연인의 대화 곁에서 귓속말로 데이트 일정과 장소를 제안하고는 한다 (CIO). 사용자가 부르지 않아도 스스로 개입 시점을 판단해 입을 연다는 뜻이다.
상기 두 서비스 모두 KANANA429 6월 밋업에서 언급되었던 것 같은데, 현재는 이 proactive의 정도가 다소 조정된 듯 하다. 실제로 언제, 어떤 방식으로 선톡을 걸지 서비스적으로 고민이 많다고.
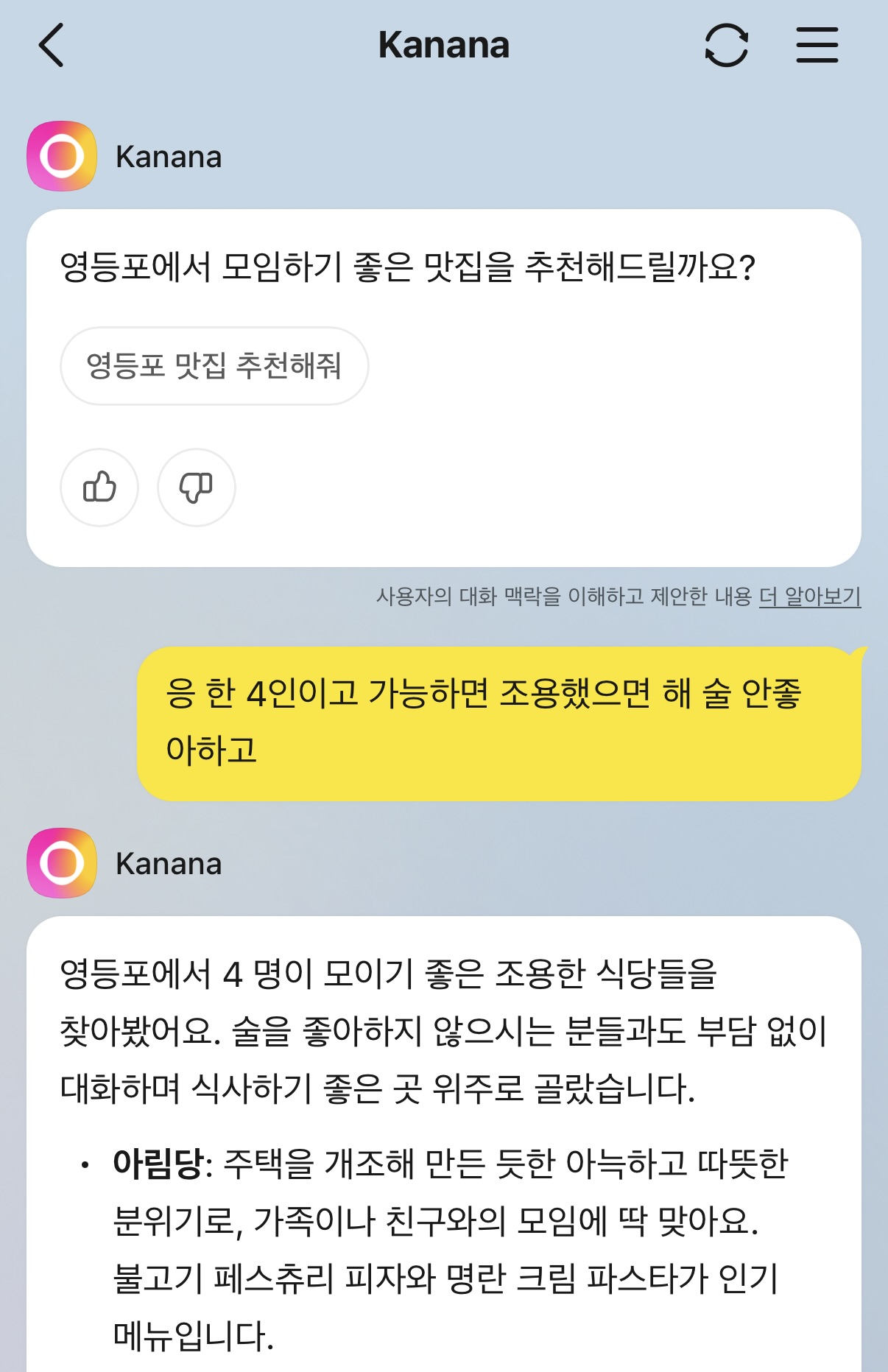
구분 축 정의
두 서비스가 갈라지는 지점을 좌표평면으로 나타내면 두 개의 축으로 정의될 것이다.
- 대화 내 위치: 대화의 참여자(participant)인가, 관찰자(observer)인가. 내가 말을 거는 상대인지, 아니면 사람들끼리의 대화를 곁에서 듣는 존재인지.
- 발화 트리거: reactive한가, proactive한가. 내가 불러야 비로소 답하는지, 아니면 개입 시점을 스스로 판단해 먼저 말을 거는지.
이 두 축 모두에서 두 서비스는 대척적으로 놓이는게 흥미로운데, @ChatGPT는 reactive participant라는 면에, 카나나는 proactive observer라는 면에 자리한다.
다만 이 두 축은 현재 비교하고자하는 두 카카오톡 내 서비스의 역할을 가르기엔 충분하지만 유일한 축은 아니다. 성격이 다른 축들이 최소 네 갈래 정도는 더 떠오르는데, 첫째, 환경이다. H2HMem이 내세우는 multi-modal/-party/-session은 사실 역할이 아니라 난이도와 구현 환경을 규정한다. 같은 사분면에 위치했다고 하더라도 몇 명의 대화를(party 수), 몇 세션에 걸쳐(memory horizon), 어떤 modality로 기억하느냐는 별개로 움직일 수 있다. 더 정교하게 접근하고자 한다면 역할과 이 환경을 분리하는 편이 유리할 것으로 보인다.
둘째, 발화 트리거의 내부 구조다. reactive/proactive는 깔끔한 이분법처럼 보이지만, 지난 내 연구들에서도 느끼는 바이나 결코 그렇지 않으며, 최근 proactive agent 연구는 “언제 말할지”를 하나의 스위치가 아니라 여러 층위로 분해한다. 가령 turn-taking 예측과 내적 동기로 발화 시점을 고르거나(Inner Thoughts, CHI 2025), 위험/불확실성을 반영한 심의로 다루거나(PRISM), full-duplex 음성까지 확장한다(τ-Voice). 즉 카나나의 위치는 다시 구체화하여 갈라질 수도 있다. (다음 포스트에서 좀 더 고민해볼 듯…)
셋째, 출력 가시성(수신 범위)이다. AI의 응답을 누가 보는가? 대화 참여자 전체인가, 나 혼자인가? 역시 앞의 두 역할 축과 독립적으로 갈린다. @ChatGPT 멘션 응답은 참여자 모두에게 공개되는(public) 반면, 카나나의 귓속말 제안은 나만 볼 수 있다(private). 같은 proactive observer라도 개입을 방 전체에 흘리느냐 당사자에게만 속삭이느냐에 따라 사용성과 프라이버시가 전혀 달라진다. (위 두 개념도의 하단 배지가 바로 이 축이다.)
넷째, 관측 범위(AI가 읽는 입력)다. 셋째가 출력을 누가 보는가였다면, 그 대칭으로 AI가 대화를 어디까지 읽는가도 갈린다. @ChatGPT는 자신이 태그된 현재 발화만 입력으로 받아 방 안의 다른 대화는 보지 못하는 반면, 카나나는 방의 대화 전체를 상시 관측한다. ‘위치’ 축(참여자/관찰자)과 맞물리지만, 관찰자 안에서도 얼마나 넓게·오래 보는가는 별도의 정도 문제라 따로 떼어볼 만하다.
Wrap-up with H2HMem
좌표평면엔 두 서비스가 점하지 않는 빈 구석중 하나를 차지하고 있다고 볼 수 있는게, 카나나와 같은 관찰자이면서도 @ChatGPT처럼 reactive한 구석을 가진 벤치마크 H2HMem이다. H2HMem의 AI는 카나나처럼 대화를 곁에서 관측하고 기억하되, @ChatGPT처럼 질의가 들어올 때만 발화한다. 논문의 formulation이 이 성격을 확실히 드러낸다.
\[a = \mathrm{LLM}\big(\mathrm{retrieve}(q, \mathcal{M}_T),\ q\big)\]저장(store) → 검색(retrieve) → 응답(answer)으로 이어지는 표준적인 외부 메모리 구조이며, 질의 $q$가 주어지지 않는 한 어떤 출력도 만들어지지 않는다.
정리해보면 아래와 같다.
| 위치 (축1) | 트리거 (축2) | 관측 범위 (AI가 읽는 대화) |
출력 가시성 (응답을 보는 사람) |
|
|---|---|---|---|---|
| @ChatGPT mention | participant | reactive | 태그된 현재 발화만 | public · 참여자 전체 |
| 카나나 | observer | proactive | 대화 전체 상시 | private · 나만(귓속말) |
| H2HMem | observer | reactive | 대화 전체 관측·기억 | 질의자에게 |
앞 두 열이 사분면의 두 축과 그대로 대응하고, 뒤 두 열은 아래 “구분 축”에서 짚은 보조 축(관측·가시성)이다.

세 대상은 한 직선이 아니라 사분면 각각에 흩어진다. 이 포스트에서 논의하지 않은 사분면 참여자이면서 proactive한 경우는 사실 agent를 상대로 대화를 하고 있는 상황으로 보는 게 맞다. 즉 대화형 가상 에이전트(캐릭터 AI)에 해당된다고 볼 수 있고, 이는 현재 assistant로서의 AI와는 결이 달라 구체적인 논의에서는 배제했다.
Future Work
H2HMem의 reactive observer라는 motivation으로부터 현재 사용 가능한 서비스를 구분해보고자 했다. multi-modal/-party/-session이라는 까다로운 환경을 포함하고 있기 때문에 평가 측면에서 “얼마나 정확히 기억했다가 질문에 되돌려주는가”로 환원하는 것을 우선으로 하고 있으나, 이 통제가 연구적 틈이자 실제 상용과의 대치되는 지점으로 보인다. 제품은 이미 proactive한 부분(카나나)까지 살피고 있는데, 최신 연구오하 벤치마크는 그 아래 reactive에 머물러 있다고 비판받을 여지도 있다. 카나나가 어느 순간에 선톡해주어야 반갑고 어느 순간엔 방해가 되는지, 그 “언제”를 H2HMem은 재지 않는다는 것이다. 정확히는, 아직 아무도 제대로 재고 있지 않을 수도 있어, 구체적인 선행 연구들을 살펴볼 필요를 느꼈다. 연구 구상