[log-22] 감정응답 LaaJ — K가 Q·M 우세 (audio)
Kanana 오디오 응답이 Qwen·MiniCPM 응답보다 명확히 우세 (overall 0.80+). 단 naturalness 축에서는 MiniCPM TTS 와 비등.
평가 대상은 log-21 과 같은 KoED 56 sample. 다만 모델들이 생성한 .wav 오디오 응답을 평가한다.
모델 라인업은 omni-modal baseline 3 종: Kanana / Qwen / MiniCPM. Human reference 는 audio 원본의 문장 단위 분리가 번거로워 일단 제외, HCX 는 본 실험 셋업에서 audio output 비활성으로 누락 (모델 자체는 지원, audio decoder + S3 storage 추가 환경 구성 필요).
Judge 는 gpt-4o-audio-preview (앞서 text output에서 활용한 gpt-5.1 은 audio input 미지원), anchor=K 로 두는 pairwise 평가 수행.
1. 평가 구성
| 구성 | 값 |
|---|---|
| Judge | gpt-4o-audio-preview |
| Anchor | K (Kanana) |
| Candidates | Q (Qwen), M (MiniCPM). P/H 제외 (Human audio reference 없음, HCX audio output 본 실험 셋업 미구성) |
| 비교 pair | (K,Q), (K,M) 2 페어 |
| 평가 sample | KoED 56 sample (기쁨/슬픔/분노/중립 각 10 + 정/한 각 8) |
| Input variant | text-bare / image-bare / audio-neutral-cut / audio-emotion-cut (4종) |
| 평가축 | empathy, naturalness (음성 prosody + 발음 포함), context 3축 + overall |
| Direction | AB·BA 양방향 (positional bias 보정) |
| 평가 단위 | 모델이 생성한 audio output wav (텍스트 응답 아님) |
| 총 verdict | 812 (K-Q 364 + K-M 448) |
verdict 분해: 모델당 56 sample × 4 variant × 2 direction = 448. K-Q 는 Qwen audio_path missing 42 sample (text-bare 15, image-bare 10, audio-N 11, audio-E 6) 영향으로 364. log-21 §2.1 의 “P-Q n=728” missing 과 일치. errors 28 (judge 형식 미충족) 제거 후 §2 분석 유효 n: K-Q 354, K-M 430.
2. K winrate — direction-corrected
(text와 동일) 각 verdict 를 K(Anchor) 기준 점수로 변환: anchor=K 라서 pair[0]=K, AB direction 의 verdict ‘1’ = K win = 1.0 / BA direction 의 ‘2’ = K win = 1.0 / 반대편 = 0.0 / tie = 0.5. 같은 (sample, variant) 의 AB·BA 두 점수를 평균낸 값이 그 단위의 K winrate.
2.1 종합 (variant 4종 평균)
| pair | n | overall | empathy | naturalness | context |
|---|---|---|---|---|---|
| K vs Q (Qwen audio) | 354 | 0.825 | 0.799 | 0.620 | 0.812 |
| K vs M (MiniCPM audio) | 430 | 0.801 | 0.773 | 0.491 | 0.804 |
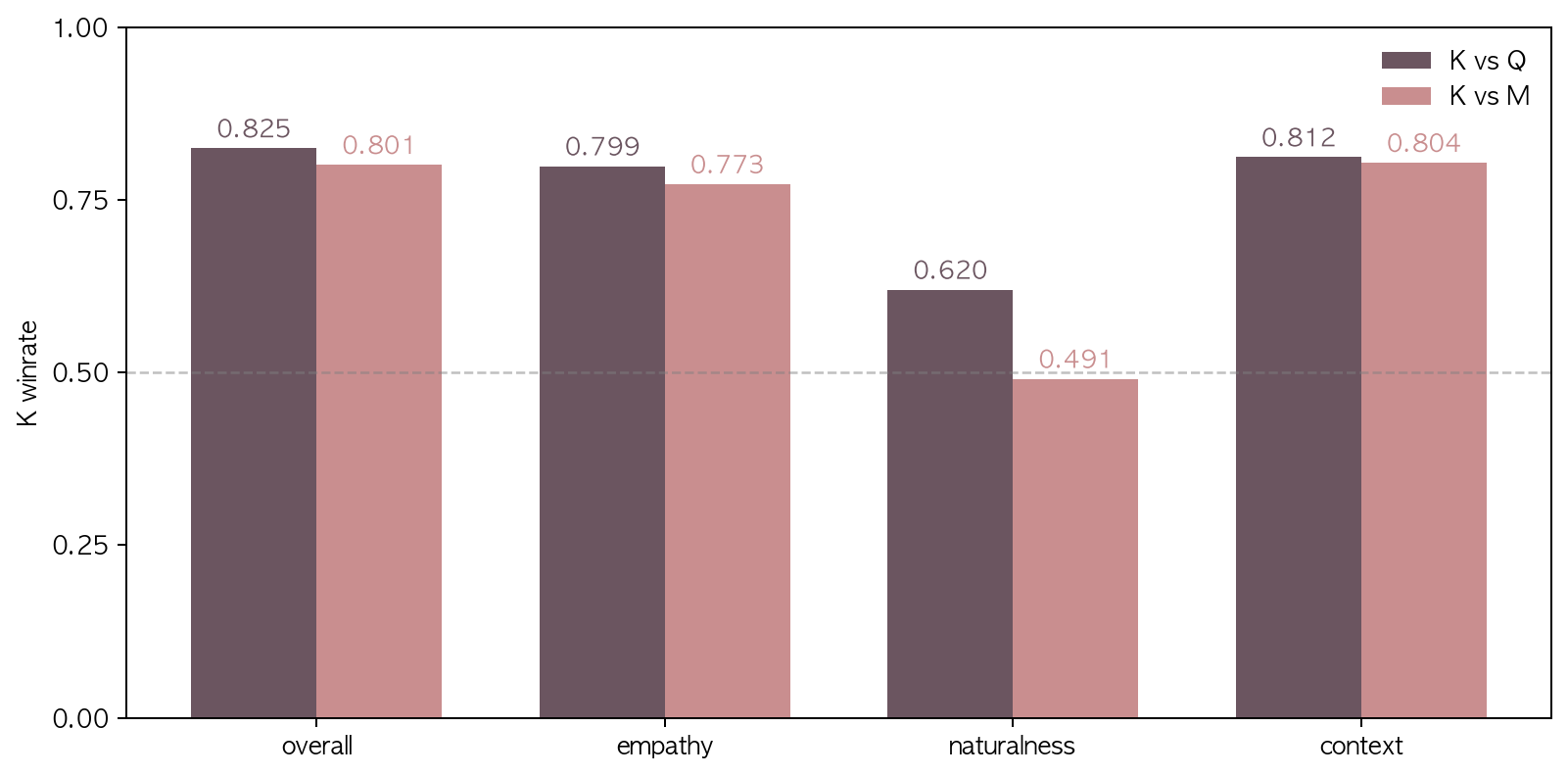
- K 가 output modality 모두에서 baseline 우위: K 가 Q·M 두 페어 모두 overall 0.80+ 로 명확히 우세. 텍스트 응답 평가 (log-21 §2.1) 에서도 이미 K ≈ P ≫ Q ≈ M (K-P 0.497 동률, Q-P 0.880, M-P 0.985) 이었으니, 오디오에서도 K > Q·M 흐름은 그 자연스러운 결과.
- Naturalness 축만 K 의 우위 폭이 좁음: K vs Q 0.620 (다른 축 0.78~0.81 대비 -0.18), K vs M 0.491 (동률, 약간 열세). axis 정의의 prosody 겹침 (§4) 으로 정밀 component 분리는 단정 어렵지만, 본 통제 setup 안 추정으로는 K 음성 응답 우위가 응답 내용·표현 차원에서 일관 발현되고 음성 합성 자체 (발음·일반 prosody) 측면에서는 baseline TTS 와 비등.
2.2 variant 별 K winrate
| pair | variant | n | overall | empathy | naturalness | context |
|---|---|---|---|---|---|---|
| K vs Q | text-bare | 81 | 0.852 | 0.863 | 0.494 | 0.844 |
| K vs Q | image-bare | 89 | 0.803 | 0.784 | 0.574 | 0.795 |
| K vs Q | audio-N | 87 | 0.828 | 0.785 | 0.686 | 0.814 |
| K vs Q | audio-E | 97 | 0.820 | 0.773 | 0.706 | 0.799 |
| K vs M | text-bare | 107 | 0.813 | 0.738 | 0.486 | 0.794 |
| K vs M | image-bare | 109 | 0.775 | 0.813 | 0.388 | 0.804 |
| K vs M | audio-N | 110 | 0.827 | 0.794 | 0.533 | 0.832 |
| K vs M | audio-E | 104 | 0.788 | 0.745 | 0.558 | 0.784 |
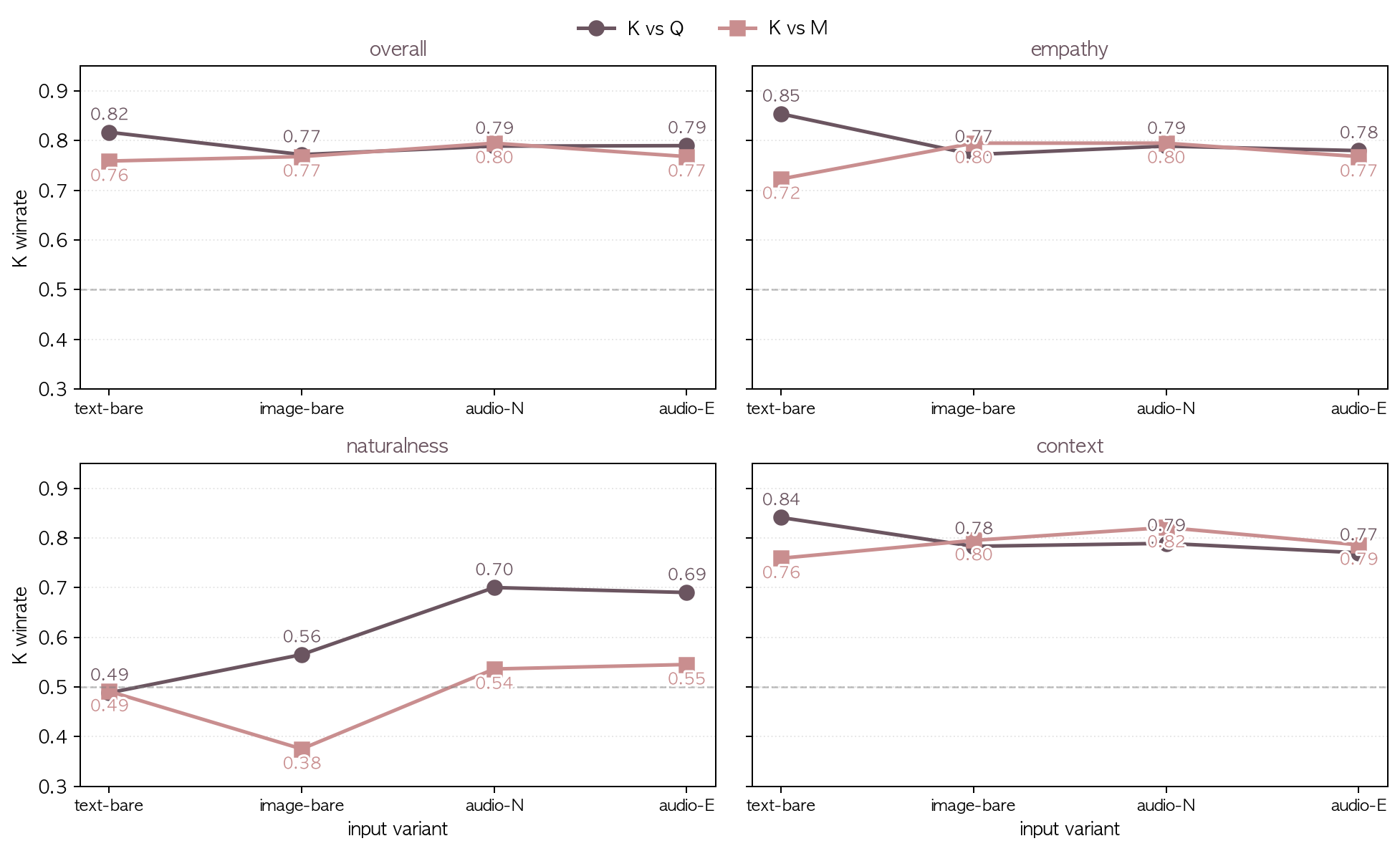
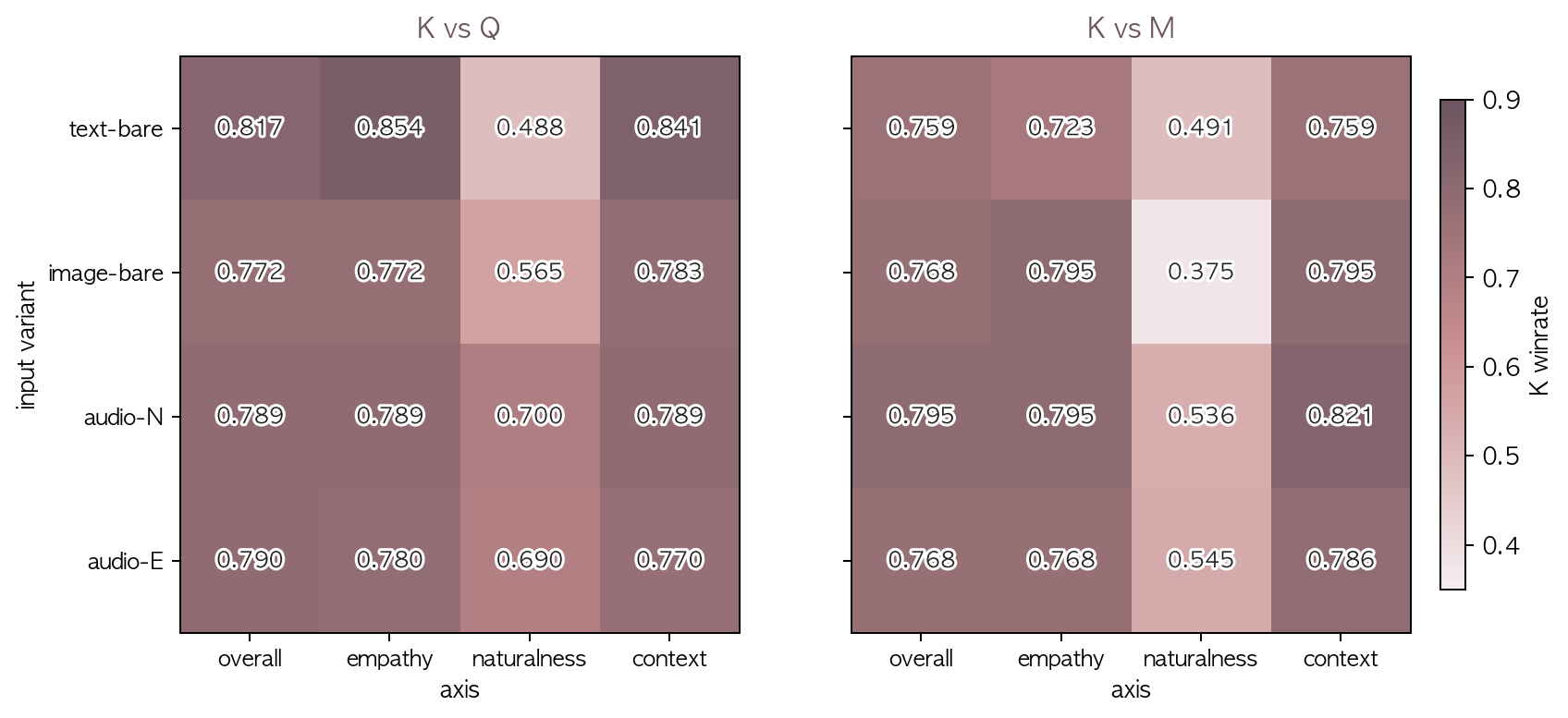
- audio input variant 에서 K 의 naturalness 우세 폭 확대 (K vs Q: text-bare 0.494 → audio-E 0.706, +0.21). K 가 audio 입력 받을 때 더 자연스러운 음성 응답을 생성한다는 모달리티-매칭 효과.
- K vs. M / image-bare / naturalness 0.388 이 가장 열세. image input 일 때 K 의 음성 응답 자연성이 M 에 명확히 열세.
- K vs. M / text-bare / naturalness 0.486 으로 K TTS 가 M TTS 와 동률.
- empathy/context 축은 0.74~0.86 으로 안정적 K 우세. variant 무관.
3. 텍스트 결과(log-21)와 대비
| 측면 | text LaaJ (log-21) | audio LaaJ (이번) |
|---|---|---|
| 비교 대상 | K vs P (Human) | K vs Q, K vs M (P/H 없음) |
| K winrate (종합) | 0.503 (≈동률) | 0.825 (vs Q), 0.801 (vs M) |
| K 가장 강한 축 | empathy 0.512 | empathy 0.77~0.80 |
| K 가장 약한 축 | naturalness 0.465 | naturalness 0.49~0.62 |
| variant 효과 | text-bare 에서만 K 우세 | text-bare 에서만 K 약함 (naturalness) |
- 공통 패턴: K 의 우위 폭이 두 modality 모두 naturalness 축에서 가장 좁음 (text K winrate 0.465 / audio 0.49~0.62). [log-21] text LaaJ 와 본 audio LaaJ 가 동일 axis (empathy / naturalness / context) 로 통제된 평가 임을 활용하면, text·audio 양쪽에서 일관된 K 우위 (overall / empathy / context) 가 LLM 응답 능력 차원의 finding 이고, naturalness 만 좁아진 점이 “출력 자체 자연성 (텍스트의 한국어 자연성 / 음성 합성 자연성) 에서는 K 의 절대적 우위가 사라진다” 의 보조 신호로 해석 가능. component-wise 단정은 axis ambiguity (§4) 한계상 어렵지만, 두 회차 일관성 자체가 추정의 근거.
- variant 효과의 비대칭: 텍스트 응답은 text input 에서 K 가장 우세 (audio input 은 도움 안 됨), 오디오 응답은 audio input 에서 K 가장 우세 (text input 은 도움 안 됨). 입력과 출력 modality 가 같을 때 K 가 그 출력에서 가장 좋다는 modality-matching 효과.
- 응답 텍스트 길이 분포 (log-21 §5.4) 가 보조 근거: K 응답이 모든 variant 에서 baseline 보다 일관되게 김 (text-bare median: K 76 / Q 46 / M 44 / HCX 22). audio LaaJ 의 K 우위가 LLM 응답 자체 풍부도에서 온다는 추정과 정합 — 단 길이 자체에 judge 가 surface 가중했을 가능성과는 본 데이터로 분리 안 됨.
4. 한계 / 검증 필요
- Human audio reference 없음. KoED 데이터셋이 텍스트 기반이라 turn 별 인간 음성 부재 — K audio 의 절대적 quality baseline 측정 불가, Q·M 상대 비교만 가능.
- axis 정의의 prosody 겹침. judge prompt 가 empathy 를 “내용 + 톤”, naturalness 를 “음성 prosody + 발음” 으로 정의해 prosody 가 두 축에 분산. judge 의 가중치 분배 불투명 → axis 별 component-wise 해석 (예: “LLM 응답 우위 / TTS 자체 비등”) 은 본 통제 setup 안에서의 추정. 정밀 분리는 axis 재정의 + 재평가 별도 실험 필요.
- Errors 28 건 (3.4%), K-M / audio-emotion-cut 에 8 건 집중. judge 가 감정 prosody 음성 듣고 평가 형식 못 따른 케이스 추정. 비율 자체는 작아 결론 영향 미미.
- 양방향 일관성 63.8%. log-21 P-K 67% 와 비슷한 수준 → audio LaaJ 자체가 text LaaJ 보다 더 noisy 한 평가는 아니라는 sanity check.