[log-20] 감정분류 — 4모델 최종 결과
평균 정답률은 MiniCPM 35% > Qwen 34% > HCX 22% > Kanana 20%. 모델이 감정 레이블 별 정확도 성능이 다르다: Kanana 는 “정” 56%, HCX 는 “중립” 75%, Qwen 은 “분노” 72%에서 강점, MiniCPM 은 상대적으로 균형.
평가 대상은 log-16 참고. 모델 라인업은 한국어 특화 2 종 (Kanana / HCX) + 다국어 omni 2 종 (Qwen / MiniCPM).
1. 4 모델 × variant 정답률
| 모델 | text-bare | image-bare | audio-neutral-cut | audio-emotion-cut | 모달 평균 |
|---|---|---|---|---|---|
| Kanana | 21.4% | 14.3% | 19.6% | 23.2% | 19.6% |
| HCX | 33.9% | 17.9% | 17.9% | 17.9% | 21.9% |
| Qwen | 37.5% | 30.4% | 30.4% | 37.5% | 33.9% |
| MiniCPM | 37.5% | 21.4% | 37.5% | 44.6% | 35.3% |
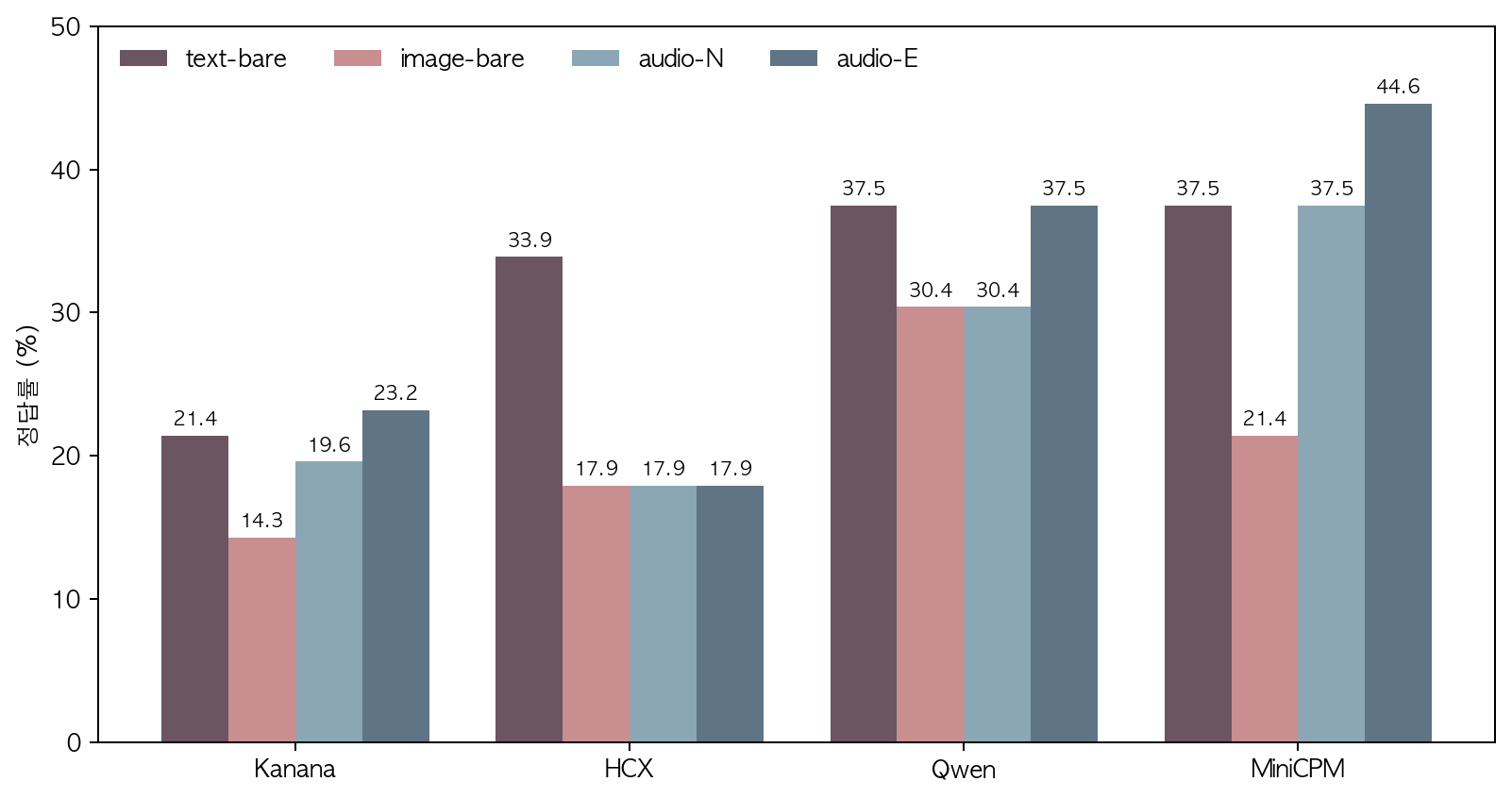
→ 최종 성능: MiniCPM 35.3% > Qwen 33.9% > HCX 21.9% > Kanana 19.6%.
Modality gap 패턴
- Kanana / Qwen / MiniCPM: audio-emotion-cut 이 가장 강함. 운율 정보가 분류에 도움 (text-only 추론에 상응 또는 우위).
- HCX 만 다른 패턴: text-bare 33.9% 압도, audio·image 는 모두 17.9% 로 변동 없음. 비-텍스트 입력에서 분류 자체가 작동하지 않고 모든 응답이 “중립” 한 레이블로 쏠림 (§2).
- image-bare: 모든 모델에서 정답률 가장 낮은 input variant (HCX 17.9%, MiniCPM 21.4%, Kanana 14.3%, Qwen 30.4%).
→ “audio 가 text 보다 강함” 은 HCX 제외 3 모델 공통. HCX 는 audio 입력에서 분류 자체가 작동하지 않고 응답이 “중립” 한 레이블로 쏠려 (§2 참조) 이 패턴에서 제외.
2. 4 모델 × 레이블 정답률 (variant 4 평균)
| 레이블 | Kanana | HCX | Qwen | MiniCPM |
|---|---|---|---|---|
| 기쁨 (10) | 17.5% | 2.5% | 45.0% | 45.0% |
| 슬픔 (10) | 15.0% | 0.0% | 40.0% | 30.0% |
| 분노 (10) | 15.0% | 10.0% | 72.5% | 57.5% |
| 중립 (10) | 15.0% | 75.0% | 30.0% | 40.0% |
| 정 (8) | 56.2% | 18.8% | 3.1% | 31.2% |
| 한 (8) | 3.1% | 25.0% | 0.0% | 0.0% |
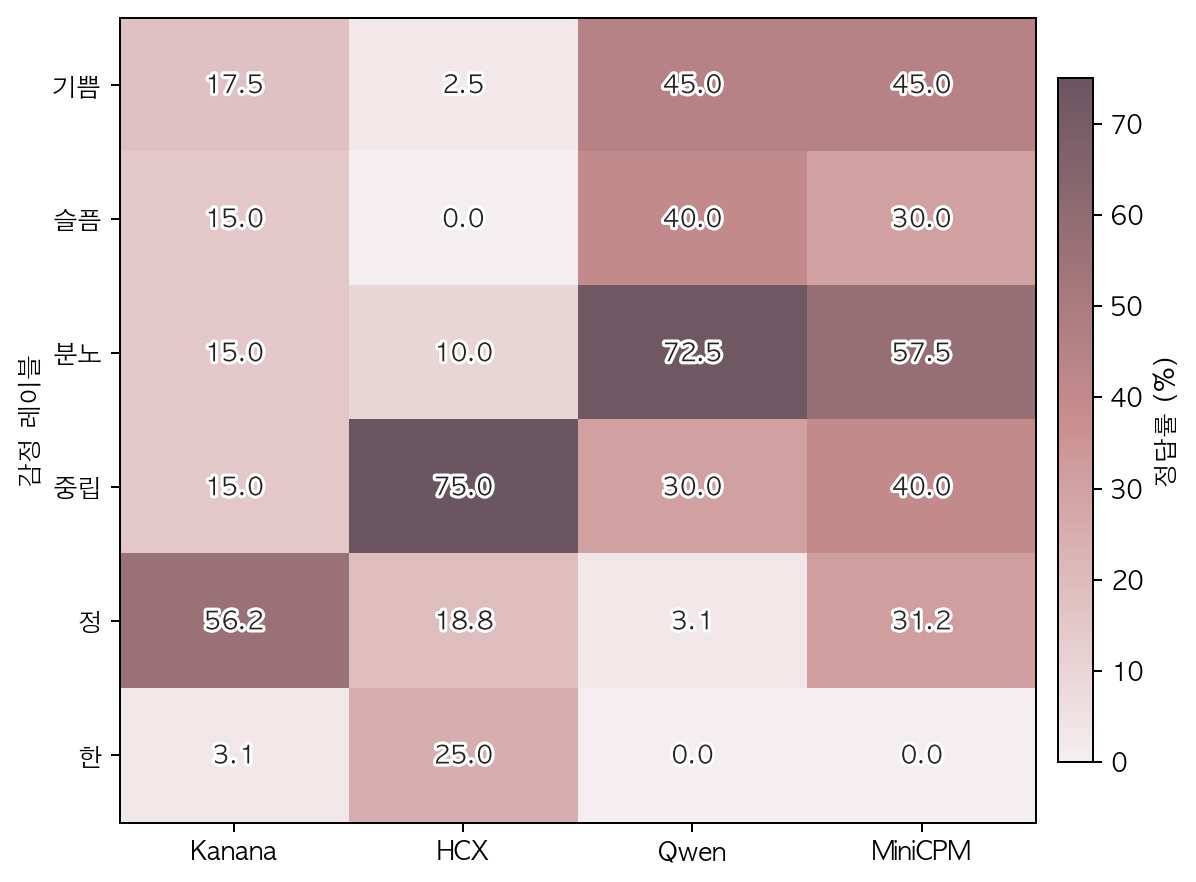
→ 모델이 레이블에 따라 정답 성능이 크게 다르다:
- Kanana: 한국어 register 레이블인 “정” 압도 (56.2%) 로 한국어 특화 효과. 단 보편 감정 (기쁨/슬픔/분노 모두 ≤17.5%) 과 “한” (3.1%) 에선 약함.
- HCX: 중립 75% 압도, 그 외 보편 감정 거의 0~10%. 강한 “중립” bias.
- Qwen: 분노 72.5% 압도, 한국어 register 레이블 (정 3.1%, 한 0%) 은 거의 못 잡음.
- MiniCPM: 균형 잡힘 (모든 보편 감정 30~57.5%), 한국어 register 레이블은 정 31.2% / 한 0%.
→ 한국어 특화 모델 2 종 (Kanana·HCX) 모두 한국어 register 레이블에서 차이가 뚜렷한데 분포는 정반대. Kanana 는 “정” 으로, HCX 는 “중립” 으로 응답이 한 레이블에 쏠림.
3. 레이블 × variant — best input variant 가 레이블마다 뒤집힘
4 모델 평균:
| 레이블 | text-bare | image-bare | audio-neutral-cut | audio-emotion-cut | best |
|---|---|---|---|---|---|
| 기쁨 | 35.0% | 12.5% | 25.0% | 37.5% | audio-E |
| 슬픔 | 15.0% | 10.0% | 27.5% | 32.5% | audio-E |
| 분노 | 57.5% | 22.5% | 35.0% | 40.0% | text |
| 중립 | 20.0% | 52.5% | 45.0% | 42.5% | image |
| 정 | 43.8% | 21.9% | 18.8% | 25.0% | text |
| 한 | 25.0% | 3.1% | 0.0% | 0.0% | text |
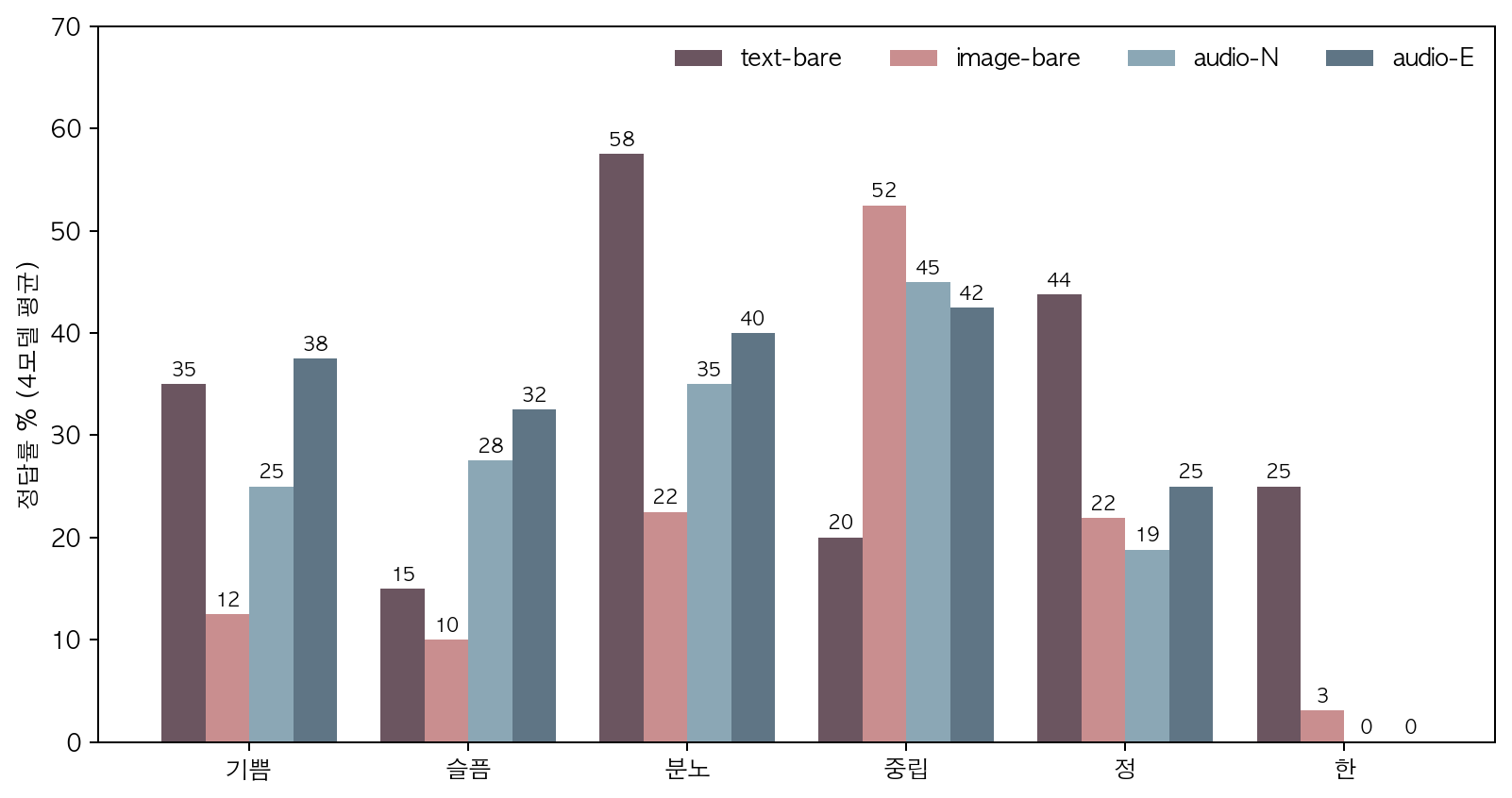
→ “audio 가 text 보다 강함” 은 기쁨·슬픔에만 해당. 분노·정·한 에서는 text 가 단연 강하고, 중립에서는 image 가 가장 강하다.
→ 지식 QA (log-13, KMMLU) 에서는 input variant 순위가 task 전반에서 “text > image > audio” 일변도였는데, 감정분류는 레이블에 따라 best input variant 가 뒤집힌다.
4. “한” 레이블 응답 분포
8 sample × 4 variant = 32 응답. 모델별 응답 분포:
| 모델 | 응답 분포 (“한” 레이블 sample 에서) |
|---|---|
| Kanana | 슬픔 22 / 정 7 / 중립 2 / 한 1 |
| HCX | 중립 24 / 한 8 |
| Qwen | 슬픔 21 / 중립 11 / 한 0 |
| MiniCPM | 슬픔 17 / 중립 9 / 분노 3 / 기쁨 1 / None 2 / 한 0 |
→ “한” 을 정답으로 선택한 횟수: HCX 8 > Kanana 1 > Qwen·MiniCPM 0. HCX 의 “한” 정답 8 회는 raw 응답 검증 결과 모두 text-bare variant 에서만 발생했고 (8/8 정답), image / audio 3 variant 는 모두 “중립” 으로 collapse. HCX 의 “한” 우위는 텍스트 입력 한정이고 modality 입력 시 작동하지 않는다 (log-17 §HCX 의 “text-bare 한 over-bias” 와 정합).
→ Kanana·Qwen·MiniCPM 이 “한” 을 본질적으로 “슬픔” 으로 인식. 한국어 “한” 의 정의 (억압된 슬픔·원망의 감정) 에 비추면 이 분류 자체는 의미상 가깝다. “한” 레이블 자체가 “슬픔” 과 의미상 독립적이지 못해서 task 설계 단계에서 감안할 문제.
5. 한국어 특화 omni 가설 — 한국어 register 레이블에서 우위
설계 시 가설: 한국어 특화 omni (HCX·Kanana) 가 한국어 register 레이블 (정·한) 에서 다국어 omni (Qwen·MiniCPM) 보다 강하다.
| 레이블 | 한국어 특화 평균 | 다국어 평균 | gap |
|---|---|---|---|
| 정 | (Kanana 56.2 + HCX 18.8) / 2 = 37.5% | (Qwen 3.1 + MiniCPM 31.2) / 2 = 17.2% | +20.3%p |
| 한 | (Kanana 3.1 + HCX 25.0) / 2 = 14.1% | (Qwen 0 + MiniCPM 0) / 2 = 0.0% | +14.1%p |
→ 두 레이블 모두 한국어 특화 평균이 위. 단 Kanana 는 “정”, HCX 는 “한” 으로 강점이 분산되어 한 모델이 둘 다 잘 잡지는 않는다. HCX 의 “한” 기여는 §4 raw 검증으로 확인됐듯 text-bare 입력 한정 (image/audio 에서는 중립 collapse), 따라서 “한” 우위는 텍스트 모드에서만 성립.
6. 결론과 의의
감정 6-way 분류 task 에서 omni 4 모델 (Kanana·HCX·Qwen·MiniCPM) 의 56/56 매트릭스를 본 결과:
-
단일 ranking 으로 모델 비교가 충분하지 않다. 평균 정답률 (MiniCPM 35% > Qwen 34% > HCX 22% > Kanana 20%) 만 보면 다국어 omni 가 우세하지만, §2 에서 보듯 모델마다 강점 레이블이 극단적으로 분기된다. 모델 비교는 레이블 단위 strength 분포로 봐야 의미가 잡힌다.
-
한국어 특화 omni 우위가 한국어 register 레이블에서 확인됐다 (§5). 정·한 두 레이블에서 한국어 특화 평균이 다국어 평균 대비 +14~20%p. 단 HCX 의 “한” 기여는 text 입력 한정이고 비-텍스트 입력에서는 분류 자체가 작동하지 않아 (§4), 한국어 특화 우위는 modality 에 따라 조건부.
-
input modality 효과는 레이블 의존적이다 (§3). 지식 QA 에서 본 “text > image > audio” 일변도와 달리, 감정분류는 best input variant 가 레이블마다 뒤집힌다 (기쁨/슬픔은 audio-emotion, 분노/정/한은 text, 중립은 image). modality 입력의 효용이 task 와 레이블 조합에 따라 달라진다는 신호.
-
task 자체가 omni 4 종 누구에게도 안정적이지 않다. 평균 정답률 19~35% 라는 절대 수준은 낮고, “한” 처럼 “슬픔” 과 의미 중첩되는 레이블은 4 모델 중 3 모델이 본질적으로 못 가른다 (§4). 후속 평가에서는 (a) 인간 annotator confusion matrix 와의 대조, (b) 레이블 정의 정련, (c) 응답 task (생성) 에서 분류 능력과의 갈림이 다음 과제.
7. 한계
-
“한” 레이블 의미상 슬픔과 분리 안 됨. 4 모델 중 3 모델이 “한” 을 “슬픔” 으로 분류. 레이블 정의 자체의 분리도 문제일 수 있어, 인간 annotator 도 같은 task 에 어떤 confusion matrix 를 보이는지 비교가 필요.
-
n=8 의 통계적 약함. “정”·”한” 두 레이블은 KoED 원본 후보가 적어 (정 14, 한 13) 거의 전수 추출. 따라서 sample 추가로 통계량 강화는 불가하고, KoED 외 한국어 register 데이터셋으로 보강 가능성 있음.