[log-21] 감정응답 LaaJ — Kanana만 인간 수준과 동급 (text)
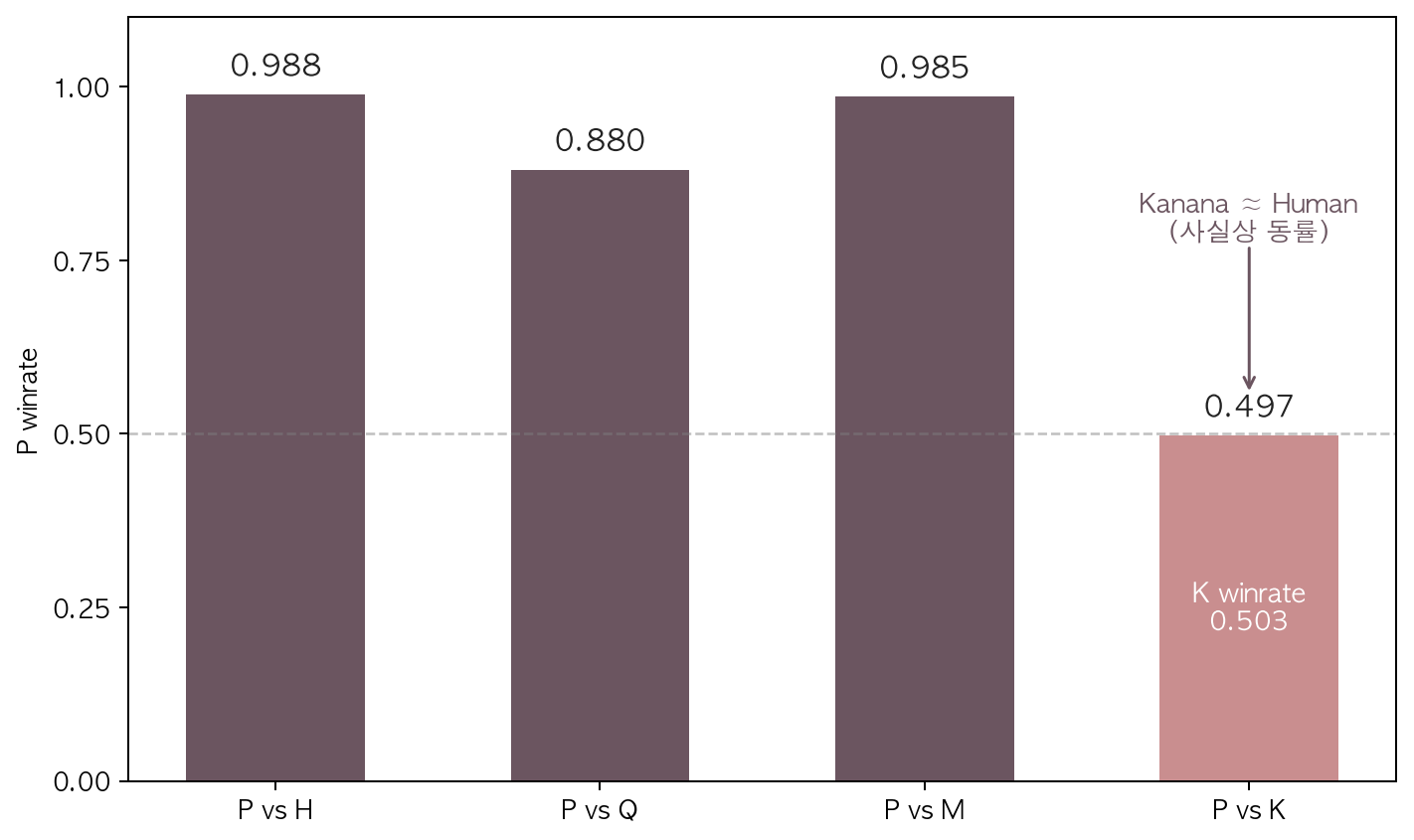
Kanana 텍스트 응답이 인간 reference 와 사실상 동률(0.50)을 기록. baseline 3가지 모델(HCX/Qwen/MiniCPM)은 인간 응답에 비교해 확실히 그 수준이 못함(0.88~0.99).
평가 대상은 KoED 한국어 감정 대화 56 sample (6개 감정: 기쁨/슬픔/분노/중립/정/한, 감정 당 8~10개 샘플). omni-modal 모델 4 종(Kanana / HCX / Qwen / MiniCPM)에 대해 텍스트 응답만 평가 수행. Judge 는 gpt-5.1, sample 별 인간 reference 응답(P) 을 anchor 로 두는 pairwise 방식으로 진행.
1. 평가 구성
| 구성 | 값 |
|---|---|
| Judge | gpt-5.1 |
| Anchor | P (인간 reference, KoED turn[-1] 실제 사람 응답) |
| Candidates | H (HCX), Q (Qwen), M (MiniCPM), K (Kanana) |
| 비교 pair | (P,H), (P,Q), (P,M), (P,K) — 4-pair |
| 평가 sample | KoED 56 sample (기쁨/슬픔/분노/중립 각 10개 + 정/한 각 8개) |
| Input variant | text-bare / image-bare / audio-neutral-cut / audio-emotion-cut (4종) |
| 평가축 | empathy (공감), naturalness (한국어 자연스러움), context (맥락 일관성) 3가지 평가 축 + overall |
| Direction | AB·BA 양방향 (positional bias 보정) |
| 총 verdict | 2,968 (P-H 896 + P-Q 728 + P-M 896 + P-K 448) |
verdict 분해: 모델당 56 sample × 4 variant × 2 direction(AB·BA 양방향) = 448 샘플에 대해 같은 쌍끼리 평균.
P-H/P-M 은 추가 보정 회차 포함으로 896,
P-Q 는 Qwen 응답 일부(42 sample) missing되어 728 (log-18 §2 의 Qwen redo 42 셀 에러 등 참고).
2. P winrate — direction-corrected
각 verdict 를 P(Anchor) 기준 점수로 변환: pair[0]=P(Human) 우세 = 1.0, pair[1](비교 모델) 우세 = 0.0, tie = 0.5. 같은 (sample, variant) 의 AB·BA 두 점수를 평균낸 값이 그 단위의 P winrate.
2.1 종합 (variant 4종 평균)
| 비교 | n | overall | empathy | naturalness | context |
|---|---|---|---|---|---|
| P vs H (HCX) | 896 | 0.988 | 0.744 | 0.717 | 0.742 |
| P vs Q (Qwen) | 728 | 0.880 | 0.700 | 0.635 | 0.681 |
| P vs M (MiniCPM) | 896 | 0.985 | 0.743 | 0.717 | 0.742 |
| P vs K (Kanana) | 448 | 0.497 | 0.488 | 0.535 | 0.497 |
-
Human reference 가 H/Q/M 모두에 압도적 우세 (0.880~0.988). 한국어 감정 응답 task 에서 비교 omni 3종 baseline이 인간 응답에 명확히 못 미친다는 신호.
-
Kanana 만 Human과 동률 (0.497). omni 4개의 baseline 중 유일. P-K 양방향 일관성 67% + naturalness 축 tie 80% (다른 페어 일관성 95%+ / naturalness tie 13~43%) 가 보조 증거. judge 가 두 응답을 구분 못 하는 비율이 압도적으로 높음, 정말 질적으로 유사하다는 강한 signal. 분포 §5.2 부록.
-
Kanana를 제외하면 Qwen 이 비교군(H/Q/M) 중 인간에 가장 가까움 (0.880). HCX·MiniCPM 은 거의 한 sample 도 이기지 못하는 수준 (0.99 가까이).
-
3축 P winrate 가 overall (0.88~0.99) 보다 우위 폭이 좁음 (H/Q/M 비교에서 0.6~0.75). 그 중 naturalness 가 가장 좁음 (0.635~0.717). 한국어 자연스러움 축에서 Human 우위 폭이 가장 작다는 뜻. 비교군 응답의 한국어 자연성 자체는 empathy·context 대비 인간 reference 에 가장 근접한다는 해석.
2.2 variant 별 P winrate
| pair | variant | n | overall | empathy | naturalness | context |
|---|---|---|---|---|---|---|
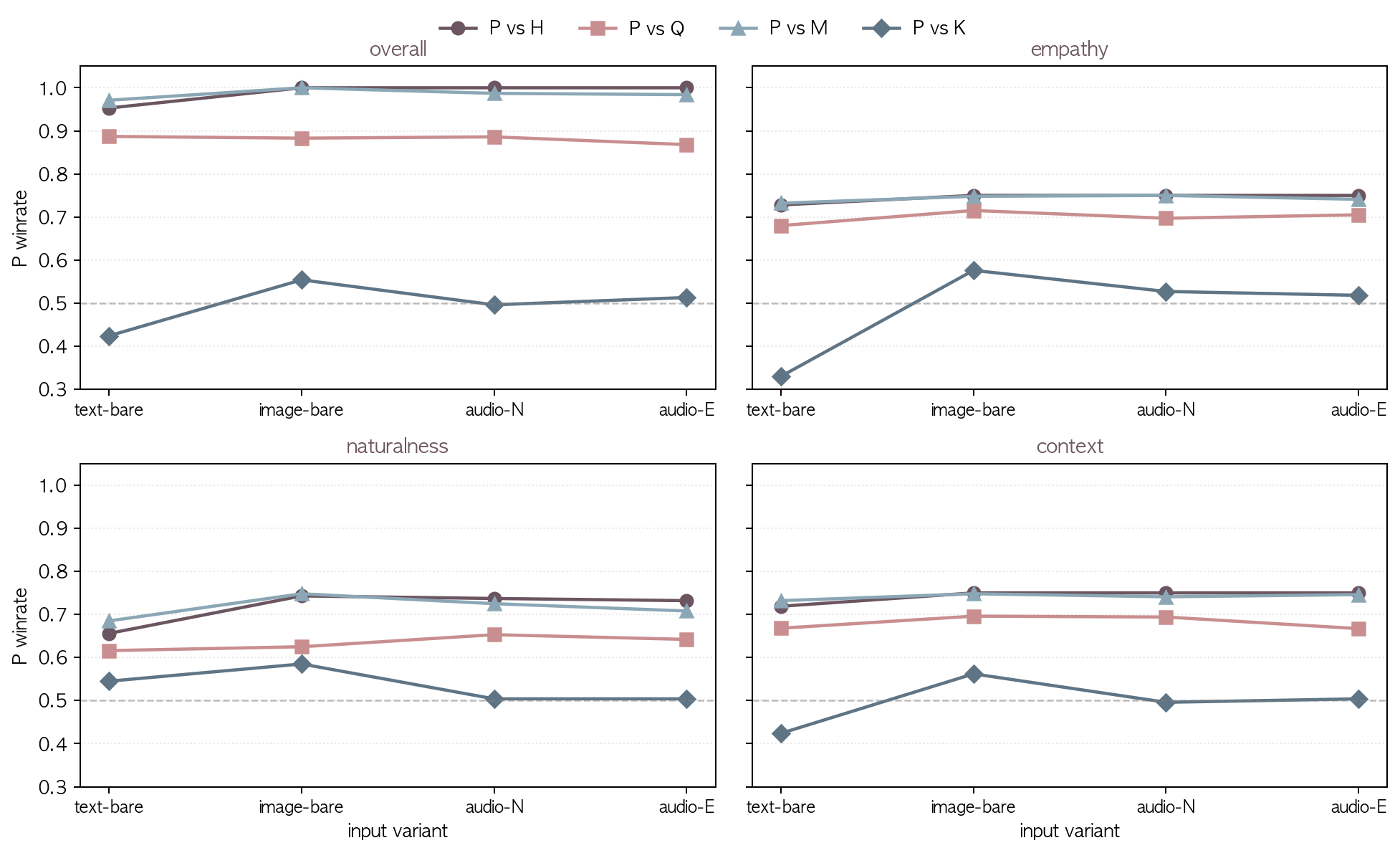
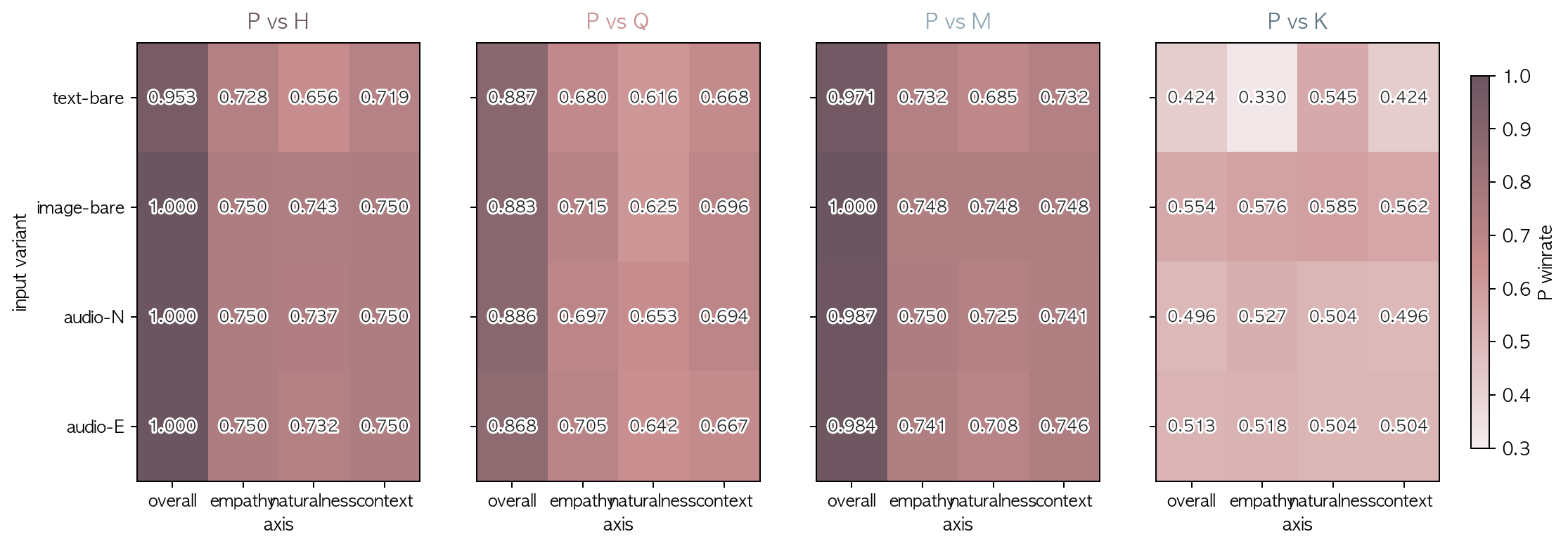
| P vs H | text-bare | 224 | 0.953 | 0.728 | 0.656 | 0.719 |
| P vs H | image-bare | 224 | 1.000 | 0.750 | 0.743 | 0.750 |
| P vs H | audio-N | 224 | 1.000 | 0.750 | 0.737 | 0.750 |
| P vs H | audio-E | 224 | 1.000 | 0.750 | 0.732 | 0.750 |
| P vs Q | text-bare | 164 | 0.887 | 0.680 | 0.616 | 0.668 |
| P vs Q | image-bare | 184 | 0.883 | 0.715 | 0.625 | 0.696 |
| P vs Q | audio-N | 180 | 0.886 | 0.697 | 0.653 | 0.694 |
| P vs Q | audio-E | 200 | 0.868 | 0.705 | 0.642 | 0.667 |
| P vs M | text-bare | 224 | 0.971 | 0.732 | 0.685 | 0.732 |
| P vs M | image-bare | 224 | 1.000 | 0.748 | 0.748 | 0.748 |
| P vs M | audio-N | 224 | 0.987 | 0.750 | 0.725 | 0.741 |
| P vs M | audio-E | 224 | 0.984 | 0.741 | 0.708 | 0.746 |
| P vs K | text-bare | 112 | 0.424 | 0.330 | 0.545 | 0.424 |
| P vs K | image-bare | 112 | 0.554 | 0.576 | 0.585 | 0.562 |
| P vs K | audio-N | 112 | 0.496 | 0.527 | 0.504 | 0.496 |
| P vs K | audio-E | 112 | 0.513 | 0.518 | 0.504 | 0.504 |
-
text-bare 가 H/Q/M 비교에서 모두 Human 우위 폭 가장 작음 (overall 0.887~0.971). 텍스트 input 만 주어졌을 때 비교 모델이 인간 reference 에 가장 근접.
-
baseline 의 modality gap: input modality 가 텍스트에서 image/audio 로 바뀌면 overall 이 1.000 가까이 확대되는 등, 같은 대화 내용을 다른 modality 로 받으면 baseline 응답이 더 약해진다.
-
K 는 text-bare 에서만 P 보다 우세 (P winrate 0.424 = K winrate 0.576), 특히 empathy 축에서 K winrate 0.670 (P 0.330) 으로 가장 큰 격차. 텍스트만 줬을 때 길이 및 구체성에서 K 가 인간 reference 보다 풍부하다는 해석.
-
K 의 약한 image/audio modality gap: K image-bare 에서 K 약간 열세 (P winrate 0.554). 같은 대화의 이미지 input 에서 K 응답도 약해진다. text-bare 0.424 → image-bare 0.554 후퇴. K audio 두 variant 는 거의 정확히 0.5. text-bare 0.424 에서 audio 에서는 동률 가까이 후퇴 (image 와 비슷한 폭).
-
naturalness 축에서 P 우위 폭이 H/Q/M 비교 전체에서 가장 좁음 (0.616~0.748). text-bare 에서 특히 두드러짐: vs H 0.656 / vs Q 0.616 / vs M 0.685 로 overall 대비 큰 폭으로 하락. baseline 의 한국어 응답 자연성 자체는 empathy/context 보다 인간에 근접하다는 해석.
-
vs H 에서 image/audio 가 모두 overall 1.000. HCX 의 image/audio input 응답이 짧고 단조로워 baseline modality gap 큼.
-
vs Q 는 variant 무관 0.87~0.89, baseline 중 modality gap 가장 작은 비교군.
-
vs M 은 image/audio 에서 1.000 가까움. MiniCPM 도 image/audio input 에서 응답이 더 형식적·단조로워져 modality gap 큼.
3. 감정분류 결과(log-20)와 대비
| 모델 | 감정분류 평균 정답률 | 감정분류 특장점 | 본 평가 P winrate |
|---|---|---|---|
| MiniCPM | 35% | “분노”·”중립” 약 50% 균형 | 0.985 (거의 못 이김) |
| Qwen | 34% | “분노” 72.5% (universal emotion) | 0.880 (비교군 중 최강) |
| HCX | 22% | “중립” 75% bias | 0.988 (거의 못 이김) |
| Kanana | 20% | “정” 56.2% (한국적 register) | 0.497 (Human 동률) |
-
감정분류와 응답 순위 역전: 분류 정답률 (MiniCPM > Qwen > HCX > Kanana) 과 응답 winrate (Kanana ≫ Qwen > MiniCPM ≈ HCX) 가 거의 반대. 레이블 분류 정답률이 자유 발화 응답 품질의 proxy 가 되지 못함.
-
Kanana 는 분류 정답률 꼴찌(20%) 임에도 응답은 Human 동률 (0.497) + image/audio modality gap 도 약함 (§2.2). 한국어 register·자연성 강점이 분류 점수에는 안 드러나도, 응답 품질과 modality robustness 양쪽으로 일관되게 나타나는 패턴.
-
Qwen 은 두 task 모두 비교군(H/Q/M) 중 인간에 가장 근접 (분류 정답률 34% / 응답 P winrate 0.880) + modality gap 도 가장 작음 (variant 무관 0.87~0.89, §2.2). 한국어 task 에서 다국어 omni 가 안정적 baseline 으로 기능하는 경우.
4. 한계 / 검증 필요
P-Q n=728 은 다른 pair 896 대비 19% 부족 (Qwen respond 일부 실패, log-18 §2). missing 42 sample 만 제외하고 full coverage 27 sample 만 봐도 P-Q winrate 0.904 로 결론 동일 (§5.1 부록) — winrate 자체에 미치는 영향은 작다.
5. 부록
5.1 P-Q missing 의 P winrate 영향
| 산정 | n verdict | n sample | P-Q winrate |
|---|---|---|---|
| 전체 | 728 | 56 | 0.880 |
| full coverage 만 (16 verdict 모두 받은 sample) | 432 | 27 | 0.904 |
→ Δ +0.024. “Qwen 이 비교군 중 인간에 가장 가깝다”는 결론 유지.
5.2 P-K 동률의 robustness 검증
| pair | tie (overall) | tie (naturalness) | AB·BA 일관성 |
|---|---|---|---|
| P-H | 0.2% | 13.2% | 99.1% |
| P-Q | 1.1% | 42.9% | 95.1% |
| P-M | 0.2% | 13.4% | 97.3% |
| P-K | 5.6% | 79.7% | 67.0% |
→ P-K 만 압도적 tie / 낮은 일관성. judge 가 K 와 P 를 구분 못 한다는 직접 증거로 해석 가능 (특히 naturalness 축에서 judge 가 80% 를 명시적 tie 로 답함, 다른 페어 0.2~1%). “진짜 동률” 쪽 강한 보조 증거.
5.3 추가 분석 가능성
- K 직접 비교 회차: anchor=K candidates=[K,H,Q,M] 직접 측정 (1,344 verdict, ~$15). 현재 P 통한 간접 추정 (Kanana ≈ P ≫ H/Q/M) 을 직접 측정으로 대체. 한국어 특화 2종 (K vs H) 만 필요하면 압축 (~$3.5).
- K modality gap mechanism: 응답 길이 및 구체성 차이 측정으로 image/audio modality 에서 K 우세 사라지는 원인 분리 (modality 정보 활용 실패 or 응답 형식 단조화 or 기타 다른 요인).
- LaaJ surface feature 가중: overall winrate 가 3축 산술평균 (0.74) 보다 훨씬 큰 격차 (0.99) → judge 가 종합 판단 시 응답 구조/길이/구체성에 가중 두는 패턴 의심되긴 하는데 주요 문제는 아니라고 판단.
5.4 응답 텍스트 길이 분포
각 모델 / variant 별 응답 텍스트의 median 글자 수 (Kanana 56 sample, Qwen 일부 missing 으로 48~55):
| 모델 | text-bare | image-bare | audio-N | audio-E | Human ref |
|---|---|---|---|---|---|
| Kanana | 76 | 62 | 49 | 53 | 46 |
| Qwen | 46 | 39 | 47 | 44 | 46 |
| MiniCPM | 44 | 40 | 29 | 24 | 46 |
| HCX | 22 | 25 | 19 | 19 | 46 |
본문 §2.2 의 추정·해석들이 응답 길이 데이터로 보강됨:
- K text-bare 응답이 Human ref 의 +65% (76 vs 46) — §2.2 K 가 text-bare input 에서 길이·구체성 풍부한 응답 생성한다는 추정 직접 확인.
- K 응답 길이가 modality 따라 감소 (text 76 → image 62 → audio 49~53) — §2.2 K image/audio modality gap 의 원인 후보: modality input 받을 때 응답 풍부도 자체가 줄어듦.
- Qwen 응답 길이 variant 무관 39~47 유지 — §2.2 “vs Q modality gap 가장 작음” 의 이유로 해석 가능: modality 변화에도 응답 형식이 일정하게 유지됨.
- MiniCPM audio-E median 24 (text-bare 44 대비 절반) — §2.2 “MiniCPM 이 image/audio input 에서 응답이 더 형식적·단조로워짐” 의 직접 확인.
- HCX 모든 variant 19~25 (Human ref 의 절반 이하) — §2.2 “HCX 응답이 짧고 단조로움” 의 직접 확인. modality 무관 일관되게 짧음.
caveat: K text-bare 응답이 Human 의 +65% 길이 → judge 가 길이·구체성에 surface 가중했을 가능성과 본 데이터로는 분리 안 됨. “K 가 진짜 풍부” vs “LaaJ 가 긴 응답을 호평” 의 분리는 응답 길이 vs winrate 회귀 (§5.3) 로 별도 분석 가능.